
<<Linux内核设计与实现>>读书记录
内核是什么?
操作系统有很多部分组成
但内核是核心
内核通常由:负责响应的中断程序,负责管理进程分享处理器时间的调度程序,负责管理进程地址空间的内存管理程序和网络,进程通信等系统服务组成。
系统调用?用户态?内核态?进程上下文?
内核独立于普通的应用程序,拥有受保护的内存空间和访问硬件设备的所有权限 这种系统态和被保护起来的内存空间 被称为 内核空间。
应用程序在用户空间执行,只允许使用看到某些特定的功能资源。
内核运行时,系统以内核态进入内核空间执行,
执行普通用户程序时,系统以用户态进入用户空间执行。
在系统中运行的应用程序 通过系统调用 来与内核通信,当一个应用程序执行一条系统调用,我们说内核正在代其执行,也被称为,应用程序通过系统调用 在内核空间运行,而内核被称为运行于进程上下文中
用户态切换到内核态大体分为两种;主动式和被动式。
1.被动式:就是Linux在用户态(ARM在用户模式)工作,没有主动发起请求、而被动地进入内核态;包括硬件中断和程序异常。
2.主动式:就是Linux在用户态(ARM在用户模式)工作,通过发起用户态程序发起命令请求、ARM响应进入特权模式进而Linux切入内核态;就是系统调用。
二、分析上述两种切换的原理
1.被动式原理:当硬件中断过来时,通过硬件直接给CPSR置位、ARM进入IRQ模式、Linux系统进入内核态;或者用户态代码出现异常、硬件也自动完成上述工作。
2.主动式原理:即软中断,Linux内核给用户空间开放了一个可以直接操作硬件寄存器进而引发中断的机制——系统调用。当用户态调用系统调用函数时,相应的硬件被置位引发中断、导致ARM工作模式的切换(进入IRQ模式),进而Linux进入内核态。
进程上下文
当一个进程在执行时,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文。当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下文,以便在再次执行该进程时,能够得到切换时的状态执行下去。
中断上下文
同理,中断上下文就是中断发生时,原来的进程执行被打断,那么就要把原来的那些变量保存下来,以便中断完成后再恢复。
内核特点
1.不能访问C库和标准C头文件
2.难以执行浮点数
3.GUN C
4.没有内存保护机制
5.容积小而固定的栈
6.同步和并发
7.可移植的重要性
进程管理
内核调度的对象是线程而不是进程
内核的调度对象是线程 为什么?
进程是资源分配的基本单位,线程是CPU调度的基本单位,
在linux系统中 统一都叫task,并没有区分线程与进程,线程只是实现资源共享的手段
每个线程都拥有一个独立的程序计数器,进程栈和一组进程寄存器。一个进程可以包含多个线程
进程是处于执行期程序及相关资源的总称
进程和线程什么区别?线程和协程什么区别?
线程独占哪些资源?
如果一个线程卡住了,进程会不会卡住?
一个协程卡住了,线程会不会卡住?
什么是用户态和内核态?
进程切换和线程切换
进程切换分两步:
1.切换页目录以使用新的地址空间
2.切换内核栈和硬件上下文
对于linux来说,线程和进程的最大区别就在于地址空间,对于线程切换,第1步是不需要做的,第2是进程和线程切换都要做的。
切换的性能消耗:
1、线程上下文切换和进程上下问切换一个最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
2、另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲(processor’s Translation Lookaside Buffer (TLB))或者相当的神马东西会被全部刷新,这将导致内存的访问在一段时间内相当的低效。但是在线程的切换中,不会出现这个问题
进程描述符 PCB
如果想充分使用CPU,必须对进程进行相应的管理,尽量使进程能够无缝的使用CPU。既然涉及到进程的切换,那么就会面临一个问题,进程现场的保护,当我们想切换到下一个进程的时候,上一个进程的现场我们必须管理好,即在切回来的时候现场必须是完整的。那么我们用什么来保存进程的信息呢,答案是进程描述符,每一个进程都有一个进程描述符(PCB),在进程创建的时候,生成PCB,在进程消亡的时候撤销PCB,PCB记录了操作系统所需的描述一个进程的所有信息,如打开的文件,挂起的信号量,进程状态以及地址空间等。
在Linux系统中,每一个进程都是由task_struct数据结构来描述,task_struct就是我们平时所说的PCB,当我们fork()一个进程时,操作系统会为我们生成一个PCB,然后从父进程那里继承一些数据,并同时把新进程插入到进程树中,以待进行管理。
我们可以先理论推导一下task_struct都有哪些字段组成:
1、进程的状态,记录进程在等待,运行,或者死锁
2、调度信息,由哪个函数调度,怎样调度等
3、进程的通讯状态
4、进程上下文和内核上下文
5、进程的父子兄弟指针,当然也是task_struct类型
6、内存信息
7、处理器上下文
内核把进程的列表存放在叫任务队列的双向循环链表中。
链表的每一项都是task_struct 也就是进程描述符结构
进程描述符的分配
进程描述符的存放
进程状态
进程上下文
当程序执行了系统调用或者触发了某个异常,它就陷入了内核空间,此时,内核代表进程执行,并处于进程上下文中,
内核所处的操作模式,此时内核代表进程执行
进程家族树
linux中所有进程都是PID=1的子进程,内核在系统启动的最后阶段启动init进程,系统中每个进程必有一个父进程,也有0或多个子进程 其关系存放进程描述符中,每个task_struct 都包含一个指向父进程的task_struct
叫parent指针, 还包含一个children的子进程链表。
进程创建
在Linux内核中,并没有线程这个概念,线程都当进程来出来,只不过可以与其他进程共享资源。
linux中 线程只是一种实现共享资源的手段,(是否共享地址空间 几乎是进程 和 linux上线程本质上唯一区别)
在其他系统中,线程被抽象为一种耗费较少资源,运行迅速的执行单元
在专门支持线程的系统中,进程通常会包含一个指向多个线程指针的进程描述符,它专门负责描述例如地址空间,打开文件这类共享资源,而线程本身再去描述它自己独占的资源。
相反在linux中如需要一个拥有4个线程的进程,linux将创建4个进程并分配4个普通的task_struct结构,并指定这4个进程共享某些资源。
内核线程
内核线程与普通进程的区别在于内核线程没有独立的地址空间,他们只在内核运行,从不到用户空间去
虚拟内存
电脑或手机开机以后,上电跑启动代码,运行OS内核,内核里也有线程,这个我们把它叫做内核态。
内核启动以后, 内核将物理内存管理起来。内核提供虚拟内存管理机制给每个进程(应用程序App)内存服务。
它的思路是什么呢?每个进程(应用App) 都有自己的虚拟内存空间,注意这里的空间只是一个数字空间,没有划分实际的物理内存。
这样做的好处是多个进程(应用App)内存都是独立的相互不影响,物理内存只有一个,多个进程(应用App)不会因为直接使用物理内存而冲突。
那么OS是如何管理物理内存的呢?进程(应用App)需要内存的时候,OS分配一块虚拟内存(起点—终点),然后OS在从自己管理的物理内存里面分配出来物理内存页,然后通过一个MMU的单元,将分配的虚拟内存与物理内存页映射起来,这样,读写虚拟内存地址最终通过映射来使用物理内存地址,这样每个进程之间的内存是独立的,安全的。每个进程会把虚拟内存空间分成4个段(代码段, 数据端,堆,栈)
代码段:用来存放进程(应用App)的代码指令。
数据端:用来存放全局变量的内存。
堆:调用os的malloc/free 来动态分配的内存。
栈:用来存放局部变量,函数参数,函数调用与跳转。
每个进程(应用App)相当于一个容器,所有应用App里面需要的资源和机制都在进程里面。
线程是OS独立调度执行的单元,OS调度执行的单位就是线程,线程需要以进程作为容器和使用进程相关的环境。
应用态没有进程就不会有线程。
进程可能更像一个容器提供了很多资源,线程是调度执行的单位,基于这个容器来创建,在容器中运行也就是进程中活动对象
在linux中 进程和线程并没有本质区分,创建一个进程也就是创建一个线程, 创建一个拥有4个线程的进程,就是创建4个进程分配4个taskstruct 并指定他们共享某些资源(地址空间).
在专门支持线程的系统中,进程通常会包含一个指向多个线程指针的进程描述符,它专门负责描述例如地址空间,打开文件这类共享资源,而线程本身再去描述它自己独占的资源。此时线程被抽象成了一种轻量级进程
问题
进程是什么?线程是什么?其区别是什么?
首先 在linux中 线程只是个逻辑概念,所有线程都被当做能与其他进程共享某些资源的进程,都被统一分配taskstruct也就是PCB,他只是实现资源共享的一种手段。
例如 创建一个拥有4个线程的进程,linux仅仅是创建4个进程并分配4个taskstruct也就是PCB 并指定他们共享某些资源.
所以在linux此类系统中 创建进程的开销和创建线程的开销 可能没有很大差距, 切换开销呢?
此处可以说说协程
在专门支持线程的系统中,进程通常会包含一个指向多个线程指针的进程描述符,它专门负责描述例如地址空间,打开文件这类共享资源,而线程本身再去描述它自己独占的资源。此时线程被抽象成了一种轻量级进程
在此类系统中进程更类似一个容器,描述了执行的程序代码的各种资源和实时结果,是处于执行期的程序以及相关资源的总称,
线程是在进程中活动的对象,所以一个进程中的多个线程可以共享内存和地址空间。
进程是资源划分的基本单位,线程是CPU调度的基本单位
内核态 用户态 需要仔细整理回答 https://zhuanlan.zhihu.com/p/447488276
运行 Ring0 级别指令的叫内核态,运行 Ring3 级别指令的叫用户态。
通过简单的例子 例如文件的copy
进程和线程什么区别?线程和协程什么区别?
线程独占哪些资源?
如果一个线程卡住了,进程会不会卡住?
一个协程卡住了,线程会不会卡住?
什么是用户态和内核态?
进程内部都有哪些数据?
为什么创建进程的成本很高?
线程间到底共享了哪些进程资源 - 知乎 (zhihu.com)
程序创建进程
终于有人把进程与线程讲清楚了 - 知乎 (zhihu.com)
进程通信方式
https://www.jianshu.com/p/1aa6533371e2
共享存储与线程局部存储
https://blog.csdn.net/jggyff/article/details/83856176
进程的终结
孤儿进程和僵尸进程
我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
进程调度
一篇文章彻底弄懂进程和线程调度 - 知乎 (zhihu.com)
IO消耗性和处理器消耗性
文本编辑器 交互 io消耗 应该被分配更多的时间 因为是交互 实时需要 更高的优先级
视频解码 处理器消耗 可以不太关心完成时间
分配处理器使用比
CFS 完全公平调度
CFS 使用红黑树来组织可运行的进程队列,并利用其迅速找到vruntime值的进程
CFS实现
1.时间记账
调度实体结构
CFS不再有时间片的概念,所以他必须维护每个进程的时间记账,每个进程旨在分配给他的时间内运行。
一个名字叫se的成员变量,嵌入再进程描述符 stask_struct内
虚拟实时
使用vruntime来记录一个程序到底运行了多长时间和他应该还再运行多久
系统调用
系统调用再用户空间进程和硬件设备中添加了一个中间层,
1.提供一种硬件的抽象接口
2.保护系统的稳定和安全,让内核可以提供基于权限的访问控制等限制策略
3.如果应用程序都能随意访问硬件而内核对此一无所知,几乎没法实现多任务和虚拟内存.
用户空间的程序无法直接执行内核代码,所以应用程序应该以某种方式通知系统,告诉内核字节需要执行一个系统调用,这样内核就可以代表应用程序再内核空间执行系统调用
通知内核的技术是中断:通过引发一个异常来促使系统切换到内核态去执行处理程序,此时的异常处理程序实际上就是系统调用处理程序,因为所有系统调用陷入内核的方式都意义,所以需要把系统调用号一并传入内核。(检查sys call table 系统调用表,没有就返回ENOSYS)
在x86种 系统调用号通过eax寄存器来传递给内核,在陷入内核之前,用户空间就把对应的系统调用号放入eax寄存器,系统调用处理程序会从eax中得到数据.
哪些常见的系统调用?
gettimeofday,getpid …),没有副作用的系统调用
对于大多数系统调用(如open,read,send,mmap…。)
syscalltable中存放了系统调用号
x86(-64) 上共有int 80, sysenter, syscall三种方式来实现系统调用
int 80 是最传统的调用方式,其通过中断/异常来实现。sysenter 与 syscall 则都是通过引入新的寄存器组( Model-Specific Register(MSR))存放所需信息,进而实现快速跳转。
- SYSCALL是在x86-64上进入内核模式的默认方法。该指令在Intel处理器的32位操作模式下不可用。
- SYSENTER是最常用于以32位操作模式调用系统调用的指令。它与SYSCALL相似,但使用起来有点困难,但这是内核的关注点。
- int 0x80是调用系统调用的传统方法,应避免使用。
[原创]简析syscall,sysret和sysenter,sysexit的具体过程
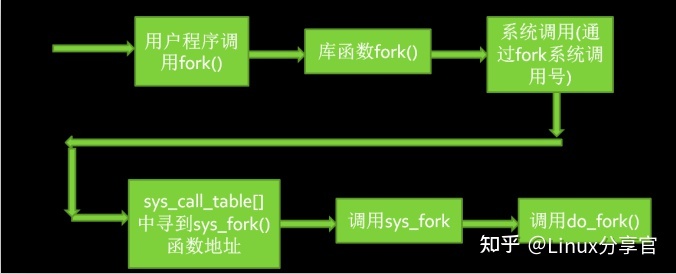
Linux下用于创建进程的API有三个fork,vfork和clone,这三个函数分别是通过系统调用sys_fork,sys_vfork以及sys_clone实现的
(这里目前讨论的都是基于x86架构的)。而且这三个系统调用,都是通过do_fork来实现的,只是传入了不同的参数。所以我们可以得出结论:所有的子进程是在do_fork实现创建和调用的。下面我们就来整理一下整个进程的在用户态到内核态的过程是怎么样的。fork系统调用如下:
内核数据结构
内核中,链表实现不是将数据结构塞入链表,而是将链表节点塞入数据结构。
正常实现,通常是在数据结构中嵌入一个链表指针
1 | struct stu{ |
在内核中的链表实现(在头文件<linux/list>中)
1 | struct list_head{ |
此方法可以轻松的把我们数据结构改为链表并交由链表内核管理。
中断和中断处理
软中断,硬中断,异常
一个设备 - 》 产生不同中断 -》对应不同中断处理程序(驱动的一个部分)
中断的上半部 和 下半部
上半部 - 立即执行中断,有严格是时限
下半部 - 被允许稍后执行的部分
网卡的例子
中断处理机制的实现
能够禁止系统中所有处理器上的中断 cli()使用sti()激活
中断这一章看的不太懂,需要回看 特别是小结(第7章)
中断的下半部分 : 用于指中断处理流程中推后执行的那一部分。
为什么要用下半部:要尽力缩短中断处理程序的执行,解决方法就是把尽可能多的工作放到下半部份解决,上半部分越快返回越好
内核提供了3种不同形式的下半部分实现机制:软中断,tasklets和工作队列
临界区的概念
访问和操作共享数据的代码段
内核同步方法:
原子操作
原子位操作
原子整数操作
自旋锁
Linux最常用的锁 自旋锁最多能被一个线程持有,如果一个线程试图去获取一个已经被争用的自旋锁,那么该线程会一直循环检查锁是否被释放,直到其重新可用。
一个被争用的自旋锁使得请求它的线程在等待锁重新可用时自旋(特别浪费处理器时间)所以自旋锁不应该被长期持有,比较适合短期进行轻量级的加锁。
读写自旋锁
读锁 可以被多个任务并发持有,写锁 最多只能被一个写任务持有。
信号量
信号量是一种睡眠锁,如果有一个任务获取一个不可用的信号量,信号量将其推进一个等待队列,然后让其睡眠,这个时候处理器能重新处理其余程序,当持有的信号量被释放后,处于等待队列的任务将被唤醒,并获得该信号量。
自旋锁与信号量
信号量因为不需要等待 所以有更好的处理器利用率,但信号量比自旋锁有更大的开销(睡眠,维护等待队列以及唤醒锁花费)
- 由于信号量的进程再等待锁重新变为可用时会睡眠,所以信号量适用于锁被长时间持有的情况
- 锁持有时间短的情况,使用信号量就不太适宜了,因为睡眠,维护等待队列以及唤醒锁花费的开销比锁占用的全部时长还要长
- 占用信号量的时候不能占用自旋锁,因为在你等待信号量时可能会睡眠,而持有自旋锁时是不允许睡眠的。
信号量还有个特性是允许拥有任意数量的锁持有者,而自旋锁一时刻最多允许一个任务持有他,对于信号量计数器=1时的情况 叫互斥信号量,(就像能睡眠的自旋锁)大于一被成为计数信号量。
读写信号量 - 互斥
mutex 互斥体
一个更简单的睡眠锁(信号量使用与较复杂的长期,简单的场景锁使用信号量不方便)
顺序锁 seq锁
主要依靠一个序列值,对于有异议的数据写入时会加锁并且序列值增加,在读取前后都会得到一个计数器,若相同则没有被写操作打断过,
死锁
原因:
线程 相互持有对方需要的资源 导致双方都一直等待对方释放资源
解决:
1.设置超时时间 终止其中某个线程
2.破坏不可抢占调节,一旦资源访问被拒绝就释放自己资源,或者比较优先级
3.资源请求放入队列中
时间管理
内存管理(重点复看)
页表
区
内存分配机制
slab分配器
页分配器
https://baike.baidu.com/item/slab/5803993?fr=aladdin
内存管理-slab原理] - DoOrDie - 博客园 (cnblogs.com)
页分配器只能按页为单位进行内存分配,但对于不足一页的申请,如果依然按一页来分配,就会造成内存的浪费,slab分配器就是为了完成小内存的分配和管理的。slab分配器建立在页分配器之上,它最终也是从页分配器申请得到整页内存,但是它对页内内存进行了更细化的管理,这一套机制有助于缓解内碎片问题。
设计思想
slab分配器把内存区看作对象来进行管理,并对外提供申请和释放的接口。它的核心是维护一个slab高速缓存,当外部请求对象时,slab会创建并初始化对象,而在释放时,并不会立即释放内存,而是放入slab高速缓存中进行维护,由此避免后续请求导致的反复创建和初始化。
栈上的静态分配
高端内存映射
永久映射
临时映射
高端内存不能永久地映射到内核地址空间上,永久映射的数量时有限制的
每个CPU的分配
使用每个CPU的原因
IO设备(重点复看)
块设备 字符设备 (块设备 支持随机访问 字符设备 顺序访问)
目前内核中块IO操作的基本容器是由BIO结构体表示,每一个块请求都通过一个BIO结构体表示。
负责提交IO请求的系统叫IO调度 程序 管理块设备的请求队列,为了优化寻址操作,内核即不会简单地按请求接受次序,也不会立即提交给磁盘。
IO调度程序(电梯调度)
两种方法减少磁盘寻址时间:合并和排序。把两个或多个请求合并成新请求
缺点 没有检查驻留过长问题,导致饥饿 特别是读饥饿
最后期限IO调度
读请求超时 500ms 写5s
预测IO调度程序
请求提交后并不直接返回处理其他请求,而是有意空闲片刻,这对应用程序来说是个处理读请求的好机会。
完全公正的排队IO调度
和上述调度有根本不同
空操作调度
只把新请求相邻的请求合并,其余什么都不做,顺序执行。主要用在块设备,真正随机访问的设备
进程的地址空间
内核除了要管理本身的内存外,还要管理用户空间中的进程内存,我们称这个内存为进程的地址空间。
进程的地址空间:由进程可寻址的虚拟内存组成,内核允许访问虚拟内存中的地址。
每个进程都有唯一的平坦的地址空间(平坦代表连续,不连续的 称为段地址空间),若一个进程的地址空间与另一个进程的地址空间有相同的内存地址,实际上彼此也互不相干,我们称这样的进程叫线程。
内存地址:是一个给定的值,要在地址空间范围之内,
一个进程可以寻址4G的虚拟内存 并不代表有权访问所有的虚拟地址,所以在地址空间中 我们更关心虚拟内存的地址空间,如 0804800-0804c000 这段可以被进程访问的合法空间为内存区域
通过内核 进程可以给自己地址空间动态的增加减少内存区域。
进程只能访问有效内存区域内的内存地址。
如果一个进程访问了不在有效范围内的内存区域,或以不正确的方式访问,内核就会终止该进程,返回 “段错误”
内存区域:
包含各种内存对象
(1)可执行文件代码的内存映射,代码段
(2)可执行文件的以初始化全局变量的内存映射,数据段
(3)未初始化的全局变量,也就是BSS段的零页的内存映射(规定未初始化的全局变量要赋默认值,所以内核要将未赋值的变量加载到内存中,然后将零页映射到该片内存上,于是这些未初始化的变量就被赋值为了0,避免了在目标文件中进行显示的初始化,减少空间浪费)
(4)进程用户空间栈的零页内存映射
(5)内存映射文件,共享内存段,匿名的内存映射,比如malloc分配的内存
进程地址空间中任何有效地址都只能位于唯一的区域,这些内存区域不能互相覆盖,不同内存片段都对应一个独立的内存区域:栈,对象代码,全局变量,被映射的文件等。
linux的进程地址空间划分_驿站Eventually的博客-CSDN博客_进程地址空间分为哪些部分
内存描述符
内核使用内存描述符 表示进程的地址空间,由mm_struct结构体表示 包含了和地址空间有关的全部信息。
mmap 和 mm_rb这两个数据结构描述了相同的对象,该地址空间的全部内存区域。
前者时链表形势存放 后者是红黑树的形式存放, mmap作为聊表 能高效遍历元素,而mm_br能高效搜索元素(logn)。
内核线程没有进程地址空间,也没有内存描述符,这也是真正含义 没有用户删改问,因为其不要访问和任何用户空间的内存。
但对于访问内核内存,其实内核线程还是需要使用一些数据 例如 页表,未来避免内核线程为内存描述符和页表浪费内存 避免处理器像周期向新地址空间切换,内核线程将直接使用前一个进程的内存描述符。
页表
应用程序操作的对象是映射到物理内存之上的虚拟内存,但处理器操作的确实物理内存,所以当程序访问一个虚拟地址时 首先要把虚拟地址转化成物理地址,而这个转换工作就要通过页表来完成
地址转换需要把虚拟地址分段,使每段虚拟地址都作为一个索引指向页表,而页表项则指向下一级别的页表或最终物理地址。
每个进程都会有页表,每次对虚拟内存中的访问都必须转换以得到物理地址,所以页表操作的性能非常重要,为了加快搜索,往往实现一个翻译后缓器TLB 将虚拟地址到物理地址的映射缓存,当访问虚拟地址时将首先检查TLB中是否缓存了映射。
目前的改进 高端内存分配部分页表,通过写时拷贝共享页表,在fork操作中 父子进程共享页表,只有子进程修改特定页表时 内核才会创建该页表的新拷贝。此后父进程不再共享改页表项,此操作可以减少拷贝页表带来的损耗。
页高速缓存和页回写
页高速缓存(cache) 时 linux内核实现磁盘缓存 主要用来减少IO操作,具体说就是通过把磁盘中的数据缓存到物理内存中,把对磁盘访问变为对物理内存的访问
页回写 将页告诉缓存中的变更数据刷新回磁盘操作
使用原因 : 1. 由于局部性原理 第一次访问数据时缓存它,那就极有可能再次被高速缓存命中,
2. 访问磁盘的速度 远低于访问内存的速度
虚拟内存 & I/O & 零拷贝总结 - 腾讯技术工程的文章 - 知乎
写缓存:
1. 写透缓存 写操作自动更新到内存和磁盘文件,即写操作会穿透缓存到磁盘,保存了缓存的一致性。
1. 回写,程序写操作先存缓存,后端存储不会立即更新,而是将页高速缓存中被写入的页面标记为“脏”,并且加入到脏页链表中,再由一个回写进程 周期将脏页链表中的页回写到磁盘,从而达到一致性。(这里的脏 并非是指高速页缓存中的数据 而是指磁盘中已经过时的数据。)
缓存回收:
linux回收策略是通过选择干净页进行简单的替换,如果缓存中没有足够干净的页面,内核将强制地进行回写操作,以腾出更多的干净可用页。
理想的回收策略称为预测算法,想要回收最不可能使用的页,但是这种策略过于理想化无法实现。
1.最近最少使用 LRU
LRU需要跟踪每个页访问踪迹,或者至少按访问实际为序的页链表。以便能回收最老的时间戳。此策略的良好效果在于 缓存的数据越久未被访问 则越不大可能近期再次被访问。 但是对于只访问一次的文件 LRU把其放在LRU链最顶端尤其失败,当然内核并没办法一个文件只会访问一次,但是它却知道过去访问了多少次。
2.双链策略
Linux实现的是一个修改过的LRU,其维护的不是一个LRU 而是两个LRU,活跃链表与非活跃链表,出于活跃链表上的是热数据 不会被换出,而非活跃链表上的页面则是可以被换出的。
原则:1.再活跃链表中的页面必须在其被访问时就处于非活跃链表中,
2.页面从尾部加入,从头部移除。两个链表需要维持平衡,如果活跃链表过多而超过了非活跃链表,那么活跃链表的头页面被重新换到非活跃链表中,以便能再回收,
这种方式为LRU/2 更普遍的是n个链表 故称 LRU/n
其中缓存的内存页面时来自对正规文件,块设备文件和内存映射文件的读写
2.6之前内核页高速缓存不是通过基树检索,而是通过一个维护了系统所有页的全局散列表进行检索
1.锁争用严重,性能受损
2.散列表的页面 比 搜索需要的页面要大的多,因为包含了所有高速缓存中的页
3.若散列搜索失败,执行速度比希望的要慢的多
4.比其他方法消耗更多内存
flusher线程
由于页高速缓存 写操作会被延迟写入后台,当缓存中的数据比磁盘存储的数据更新时,改数据就被称为脏数据,再内存中被累计起来的脏页必须被写回磁盘,以下三种情况 脏页被写回磁盘
1.空闲内存低于一个阈值,内核必须将脏页写回磁盘以便释放内存,只要干净的内存才可以回收,内存干净后,内核就可以清理数据,最终释放更多内存
2.脏页驻留时间超过一个特定的阈值,内核必须将超时的脏页写回磁盘。
3.用户进程调用 sync() 和 fsync() 时 内核会执行回写操作
在2.6之后 由flusher线程执行这三种工作(将被周期性唤醒)
总结
从上面我们可以知道 CPU 的缓存结构一般由 L1、L2、L3 三层缓存结构组成,CPU 读取数据只与缓存交互,不会直接访问主存,所以 CPU 缓存和主存之间维护了一套映射关系。当被查找的数据发生缺失时,需要等待数据从主存加载到缓存中,如果缓存满了,那么还需要进行淘汰。如果被淘汰的数据是脏数据,那么还需要写回到主存中,写的策略有写直达(write-through)和写回(write-back)。
由于现在计算机中的 CPU 都是多核的,并且缓存数据是由多核共享的,所以就有了类似 MESI 这样的协议来维护一个状态机保证数据在多核之间是一致的。
为了访问数据安全,便捷,迅速所以加了一层虚拟内存,每个程序在启动的时候都会维护一个页表,这个页表维护了一套映射关系。CPU 操作的实际上是虚拟地址,每次需要 MMU 将虚拟地址在页表上映射成物理地址后查找数据。并且为了节省内存所以设计了多级页表,为了从页表中查找数据更快加了一个缓存芯片 TLB。
作者:腾讯技术工程
链接:https://zhuanlan.zhihu.com/p/568990751
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
需要整理的问题
线程和进程
1 | On Mon, 5 Aug 1996, Peter P. Eiserloh wrote:> > We need to keep a clear the concept of threads. Too many people> seem to confuse a thread with a process. The following discussion> does not reflect the current state of linux, but rather is an> attempt to stay at a high level discussion.NO!There is NO reason to think that "threads" and "processes" are separateentities. That's how it's traditionally done, but I personally think it's amajor mistake to think that way. The only reason to think that way ishistorical baggage. Both threads and processes are really just one thing: a "context ofexecution". Trying to artificially distinguish different cases is justself-limiting. A "context of execution", hereby called COE, is just the conglomerate of all the state of that COE. That state includes things like CPU state (registers etc), MMU state (page mappings), permission state (uid, gid) and various "communication states" (open files, signal handlers etc).Traditionally, the difference between a "thread" and a "process" has beenmainly that a threads has CPU state (+ possibly some other minimal state),while all the other context comes from the process. However, that's just_one_ way of dividing up the total state of the COE, and there is nothingthat says that it's the right way to do it. Limiting yourself to that kind ofimage is just plain stupid. The way Linux thinks about this (and the way I want things to work) is thatthere _is_ no such thing as a "process" or a "thread". There is only thetotality of the COE (called "task" by Linux). Different COE's can share partsof their context with each other, and one _subset_ of that sharing is thetraditional "thread"/"process" setup, but that should really be seen as ONLYa subset (it's an important subset, but that importance comes not fromdesign, but from standards: we obviusly want to run standards-conformingthreads programs on top of Linux too). In short: do NOT design around the thread/process way of thinking. The kernel should be designed around the COE way of thinking, and then the pthreads _library_ can export the limited pthreads interface to users who want to use that way of looking at COE's.Just as an example of what becomes possible when you think COE as opposed to thread/process:- You can do a external "cd" program, something that is traditionallyimpossible in UNIX and/or process/thread (silly example, but the idea is that you can have these kinds of "modules" that aren't limited to the traditional UNIX/threads setup). Do a:clone(CLONE_VM|CLONE_FS);child: execve("external-cd");/* the "execve()" will disassociate the VM, so the only reason we used CLONE_VM was to make the act of cloning faster */- You can do "vfork()" naturally (it meeds minimal kernel support, but that support fits the CUA way of thinking perfectly):clone(CLONE_VM);child: continue to run, eventually execve()mother: wait for execve- you can do external "IO deamons":clone(CLONE_FILES);child: open file descriptors etcmother: use the fd's the child opened and vv.All of the above work because you aren't tied to the thread/process way ofthinking. Think of a web server for example, where the CGI scripts are doneas "threads of execution". You can't do that with traditional threads,because traditional threads always have to share the whole address space, soyou'd have to link in everything you ever wanted to do in the web serveritself (a "thread" can't run another executable). Thinking of this as a "context of execution" problem instead, your tasks cannow chose to execute external programs (= separate the address space from theparent) etc if they want to, or they can for example share everything withthe parent _except_ for the file descriptors (so that the sub-"threads" canopen lots of files without the parent needing to worry about them: they closeautomatically when the sub-"thread" exits, and it doesn't use up fd's in theparent). Think of a threaded "inetd", for example. You want low overhead fork+exec, sowith the Linux way you can instead of using a "fork()" you write amulti-threaded inetd where each thread is created with just CLONE_VM (shareaddress space, but don't share file descriptors etc). Then the child canexecve if it was a external service (rlogind, for example), or maybe it wasone of the internal inetd services (echo, timeofday) in which case it justdoes it's thing and exits. You can't do that with "thread"/"process".Linus |
作者:小林coding
链接:https://www.zhihu.com/question/44087187/answer/2062919643
线程与进程的比较
线程与进程的比较如下:
- 进程是资源(包括内存、打开的文件等)分配的单位,线程是 CPU 调度的单位;
- 进程拥有一个完整的资源平台,而线程只独享必不可少的资源,如寄存器和栈;
- 线程同样具有就绪、阻塞、执行三种基本状态,同样具有状态之间的转换关系;
- 线程能减少并发执行的时间和空间开销;
对于,线程相比进程能减少开销,体现在:
- 线程的创建时间比进程快,因为进程在创建的过程中,还需要资源管理信息,比如内存管理信息、文件管理信息,而线程在创建的过程中,不会涉及这些资源管理信息,而是共享它们;
- 线程的终止时间比进程快,因为线程释放的资源相比进程少很多;
- 同一个进程内的线程切换比进程切换快,因为线程具有相同的地址空间(虚拟内存共享),这意味着同一个进程的线程都具有同一个页表,那么在切换的时候不需要切换页表。而对于进程之间的切换,切换的时候要把页表给切换掉,而页表的切换过程开销是比较大的;
- 由于同一进程的各线程间共享内存和文件资源,那么在线程之间数据传递的时候,就不需要经过内核了,这就使得线程之间的数据交互效率更高了;
所以,线程比进程不管是时间效率,还是空间效率都要高。
线程的上下文切换
在前面我们知道了,线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。
所以,所谓操作系统的任务调度,实际上的调度对象是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。
对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程;
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源,这些资源在上下文切换时是不需要修改的;
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程上下文切换的是什么?
这还得看线程是不是属于同一个进程:
- 当两个线程不是属于同一个进程,则切换的过程就跟进程上下文切换一样;
- 当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据;
所以,线程的上下文切换相比进程,开销要小很多。
线程的实现
主要有三种线程的实现方式:
- 用户线程(*User Thread*):在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理;
- 内核线程(*Kernel Thread*):在内核中实现的线程,是由内核管理的线程;
- 轻量级进程(*LightWeight Process*):在内核中来支持用户线程;
那么,这还需要考虑一个问题,用户线程和内核线程的对应关系。
进程调度切换PCB
线程调度切换TCB
除了linux内核知识本身 最大的收获还是其中一些设计方法,比如进程的写时复制,中断的上部下部。

