
深入理解Go
深入理解Go
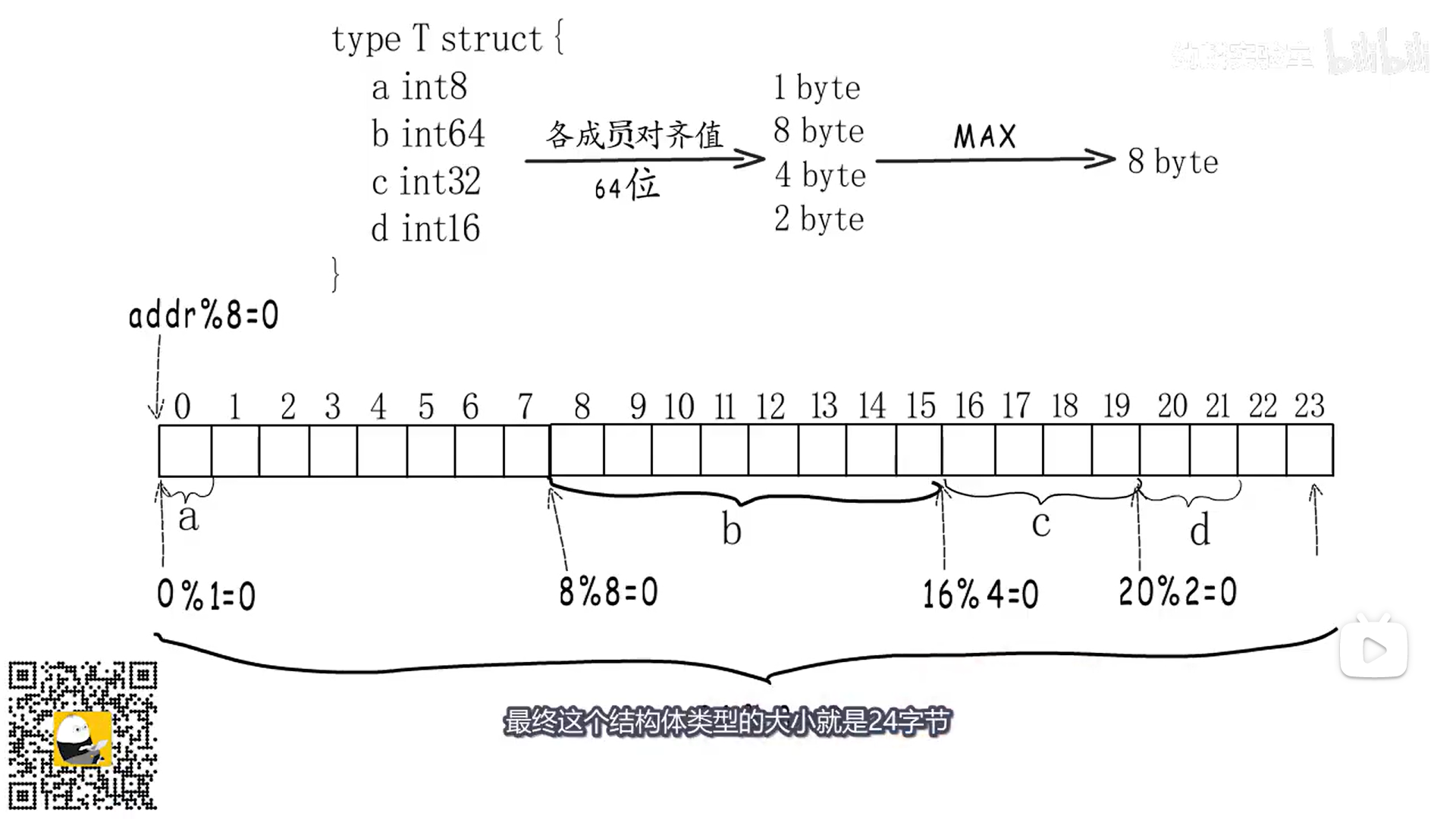
结构体内存对齐
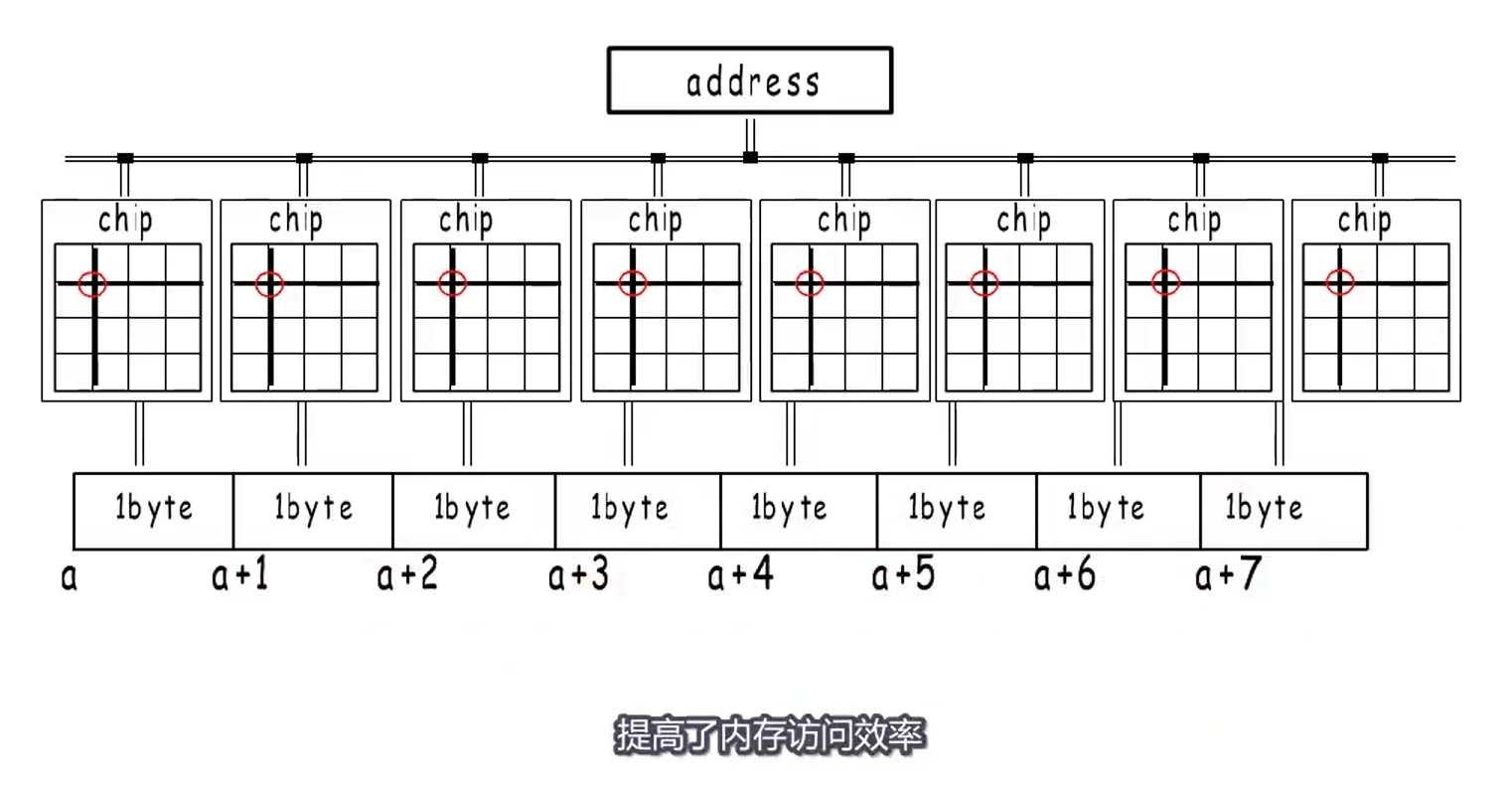
地址总线
64位 一次最小寻址 8B 机器字长 (bmap 8个k的原因?)
每次操作4byte 要32位数据总线
每次操作8byte 要64位数据总线
64位机器 cpu一次并行操作数8byte
数据类型的对齐边界 是取数据类型大小 与 平台最大对齐边界中较小的那一个。

对于结构体
每次会判断结构体中类型字节占用最大的 作为对齐边界
类型大小要是对齐边界的整数倍 不够需要扩充至整数倍
所以 map[int8]int64 若 k-v存储 由于内存对齐 会浪费7字节
数组
在不考虑逃逸分析的情况下,如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化,
如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上,这些转换后的代码才会继续进入[中间代
码生成和机器码生成两个阶段,最后生成可以执行的二进制文件。
数组作为一种基本的数据类型,我们通常会从两个维度描述数组,也就是数组中存储的元素类型和数组最大能存储的元素个数,在 Go 语言中我们往往会使用如下所示的方式来表示数组类型:
1 | [10]int |
Go 语言数组在初始化之后大小就无法改变,存储元素类型相同、但是大小不同的数组类型在 Go 语言看来也是完全不同的,只有两个条件都相同才是同一类型。
上述两种声明方式在运行期间得到的结果是完全相同的,后一种声明方式在编译期间就会被转换成前一种,这也就是编译器对数组大小的推导,
数组的长度是在编译时静态计算的,并且数组无法在运行时动态扩缩容量的。使用append报错
切片
在 Go 语言中,切片类型的声明方式与数组有一些相似,不过由于切片的长度是动态的,所以声明时只需要指定切片中的元素类型:
1 | []int |
Go
从切片的定义我们能推测出,切片在编译期间的生成的类型只会包含切片中的元素类型,即 int 或者 interface{} 等
编译期间的切片是 cmd/compile/internal/types.Slice 类型的,但是在运行时切片可以由如下的 reflect.SliceHeader 结构体表示,其中:
Data是指向数组的指针;Len是当前切片的长度;Cap是当前切片的容量,即Data数组的大小:
1 | type SliceHeader struct { |
Data 是一片连续的内存空间,这片内存空间可以用于存储切片中的全部元素,数组中的元素只是逻辑上的概念,底层存储其实都是连续的,所以我们可以将切片理解成一片连续的内存空间加上长度与容量的标识。
初始化
Go 语言中包含三种初始化切片的方式:
- 通过下标的方式获得数组或者切片的一部分;
- 使用字面量初始化新的切片;
- 使用关键字
make创建切片:
1 | arr[0:3] or slice[0:3] |
1.下标访问
使用下标创建切片是最原始也最接近汇编语言的方式,它是所有方法中最为底层的一种,编译器会将 arr[0:3] 或者 slice[0:3] 等语句转换成 OpSliceMake 操作
需要注意的是使用下标初始化切片不会拷贝原数组或者原切片中的数据,它只会创建一个指向原数组的切片结构体,所以修改新切片的数据也会修改原切片。
2.字面量
当我们使用字面量 []int{1, 2, 3} 创建新的切片时,cmd/compile/internal/gc.slicelit 函数会在编译期间将它展开成如下所示的代码片段:
1 | var vstat [3]int |
- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组;
- 将这些字面量元素存储到初始化的数组中;
- 创建一个同样指向
[3]int类型的数组指针; - 将静态存储区的数组
vstat赋值给vauto指针所在的地址; - 通过
[:]操作获取一个底层使用vauto的切片;
第 5 步中的 [:] 就是使用下标创建切片的方法,从这一点我们也能看出 [:] 操作是创建切片最底层的一种方法。
3.make关键字
如果使用字面量的方式创建切片,大部分的工作都会在编译期间完成。但是当我们使用 make 关键字创建切片时,很多工作都需要运行时的参与;调用方必须向 make 函数传入切片的大小以及可选的容量
根据下面2个条件检查
- 切片的大小和容量是否足够小;
- 切片是否发生了逃逸,最终在堆上初始化
当切片发生逃逸或者非常大时,运行时需要 runtime.makeslice 在堆上初始化切片,如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 会被直接转换成如下所示的代码:
1 | var arr [4]int |
上述代码会初始化数组并通过下标 [:3] 得到数组对应的切片,这两部分操作都会在编译阶段完成,编译器会在栈上或者静态存储区创建数组并将 [:3] 转换成上一节提到的 OpSliceMake 操作。
追加和扩容
使用 append 关键字向切片中追加元素也是常见的切片操作,中间代码生成阶段的 cmd/compile/internal/gc.state.append 方法会根据返回值是否会覆盖原变量,选择进入两种流程,如果 append 返回的新切片不需要赋值回原有的变量,就会进入如下的处理流程:
1 | // append(slice, 1, 2, 3) |
我们会先解构切片结构体获取它的数组指针、大小和容量,如果在追加元素后切片的大小大于容量,那么就会调用 runtime.growslice 对切片进行扩容并将新的元素依次加入切片。
如果使用 slice = append(slice, 1, 2, 3) 语句,那么 append 后的切片会覆盖原切片,这时 cmd/compile/internal/gc.state.append 方法会使用另一种方式展开关键字:
是否覆盖原变量的逻辑其实差不多,最大的区别在于得到的新切片是否会赋值回原变量。如果我们选择覆盖原有的变量,就不需要担心切片发生拷贝影响性能,因为 Go 语言编译器已经对这种常见的情况做出了优化。
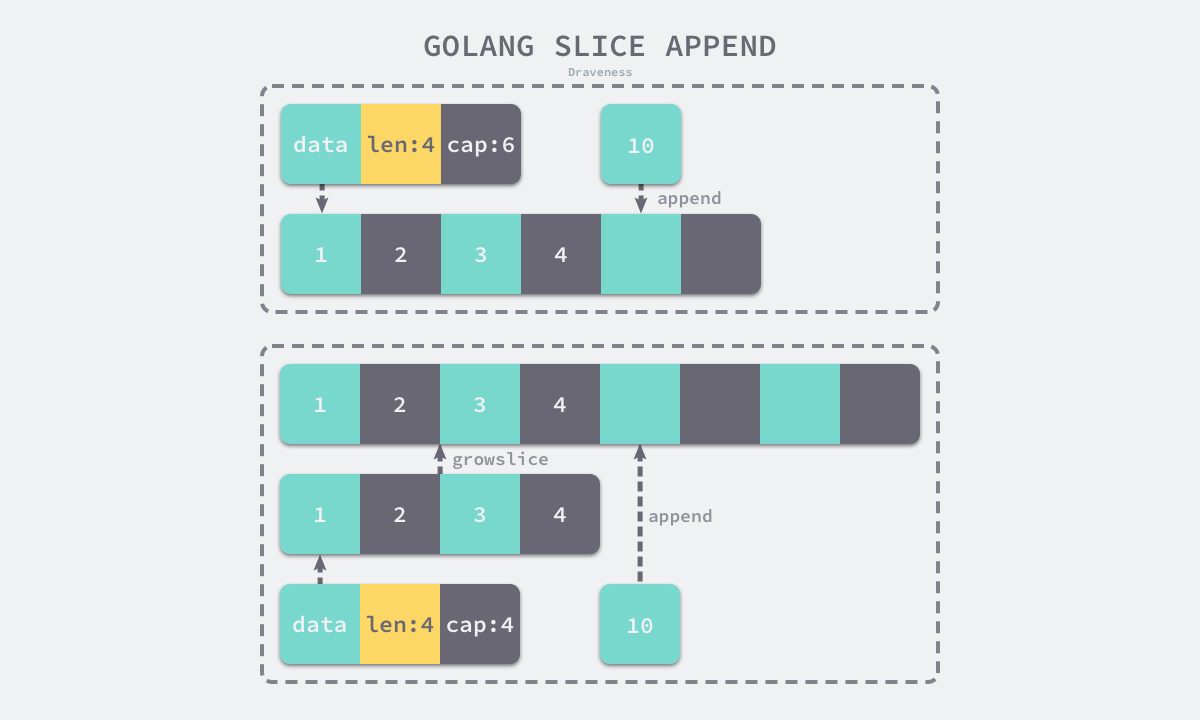
到这里我们已经清楚了 Go 语言如何在切片容量足够时向切片中追加元素,不过仍然需要研究切片容量不足时的处理流程。当切片的容量不足时,我们会调用 runtime.growslice 函数为切片扩容,扩容是为切片分配新的内存空间并拷贝原切片中元素的过程,我们先来看新切片的容量是如何确定的:
1 | func growslice(et *_type, old slice, cap int) slice { |
在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
上述代码片段仅会确定切片的大致容量,下面还需要根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会使用如下所示的代码对齐内存:
1 | var overflow bool |
runtime.roundupsize 函数会将待申请的内存向上取整,取整时会使用 runtime.class_to_size 数组,使用该数组中的整数可以提高内存的分配效率并减少碎片,我们会在内存分配一节详细介绍该数组的作用:
在默认情况下,我们会将目标容量和元素大小相乘得到占用的内存。如果计算新容量时发生了内存溢出或者请求内存超过上限,就会直接崩溃退出程序,不过这里为了减少理解的成本,将相关的代码省略了。
如果切片中元素不是指针类型,那么会调用 runtime.memclrNoHeapPointers 将超出切片当前长度的位置清空并在最后使用 runtime.memmove 将原数组内存中的内容拷贝到新申请的内存中。这两个方法都是用目标机器上的汇编指令实现的,这里就不展开介绍了。
runtime.growslice 函数最终会返回一个新的切片,其中包含了新的数组指针、大小和容量,这个返回的三元组最终会覆盖原切片。
1 | var arr []int64 |
简单总结一下扩容的过程,当我们执行上述代码时,会触发 runtime.growslice 函数扩容 arr 切片并传入期望的新容量 5,这时期望分配的内存大小为 40 字节;不过因为切片中的元素大小等于 sys.PtrSize,所以运行时会调用 runtime.roundupsize 向上取整内存的大小到 48 字节,所以新切片的容量为 48 / 8 = 6
注 sys.PtrSize
表示系统指针大小,在 32 位机器中,sys.PtrSize = 4,64 位机器中,sys.PtrSize = 8

Golang 切片(slice)扩容机制源码剖析 - 天心PHP - 博客园 (cnblogs.com)
拷贝
当使用copy(a,b)的形式对切片进行拷贝时,编译期间的 cmd/compile/internal/gc.copyany 也会分两种情况进行处理拷贝操作,如果当前 copy 不是在运行时调用的,copy(a, b) 会被直接转换成下面的代码:
1 | n := len(a) |
上述代码中的 runtime.memmove 会负责拷贝内存。而如果拷贝是在运行时发生的,例如:go copy(a, b),编译器会使用 runtime.slicecopy 替换运行期间调用的 copy.
无论是编译期间拷贝还是运行时拷贝,两种拷贝方式都会通过 runtime.memmove 将整块内存的内容拷贝到目标的内存区域中:
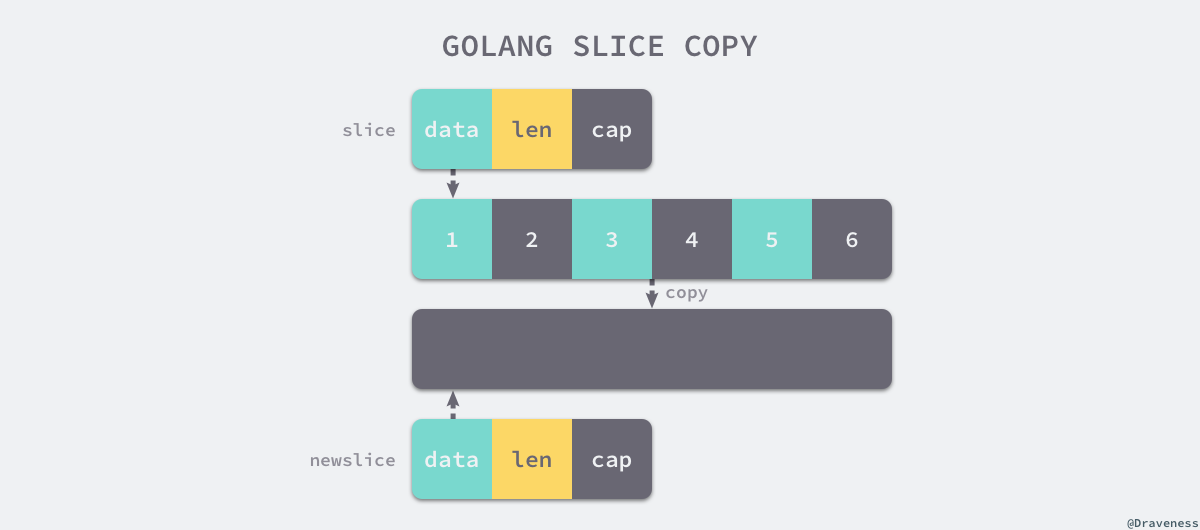
相比于依次拷贝元素,runtime.memmove 能够提供更好的性能。需要注意的是,整块拷贝内存仍然会占用非常多的资源,在大切片上执行拷贝操作时一定要注意对性能的影响。
注意
切片的很多功能都是由运行时实现的,无论是初始化切片,还是对切片进行追加或扩容都需要运行时的支持,需要注意的是在遇到大切片扩容或者复制时可能会发生大规模的内存拷贝,一定要减少类似操作避免影响程序的性能。
map哈希表
[go map数据结构和源码详解 - Jo_ZSM - 博客园 ](https://www.cnblogs.com/JoZSM/p/11784037.html#:~:text=go的map底层实现方式是hash表(C%2B%2B的map是红黑树实现,而C%2B%2B 11新增的unordered_map则与go的map类似,都是hash实现)。,go map的数据被置入一个由桶组成的有序数组中,每个桶最多可以存放8个key%2Fvalue对。)
Go 语言运行时同时使用了多个数据结构组合表示哈希表,其中 runtime.hmap 是最核心的结构体,我们先来了解一下该结构体的内部字段:
1 | type hmap struct { |
count表示当前哈希表中的元素数量;B表示当前哈希表持有的buckets数量,但是因为哈希表中桶的数量都 2 的倍数????,所以该字段会存储对数,也就是len(buckets) == 2^B;hash0是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;oldbuckets是哈希在扩容时用于保存之前buckets的字段,它的大小是当前buckets的一半;
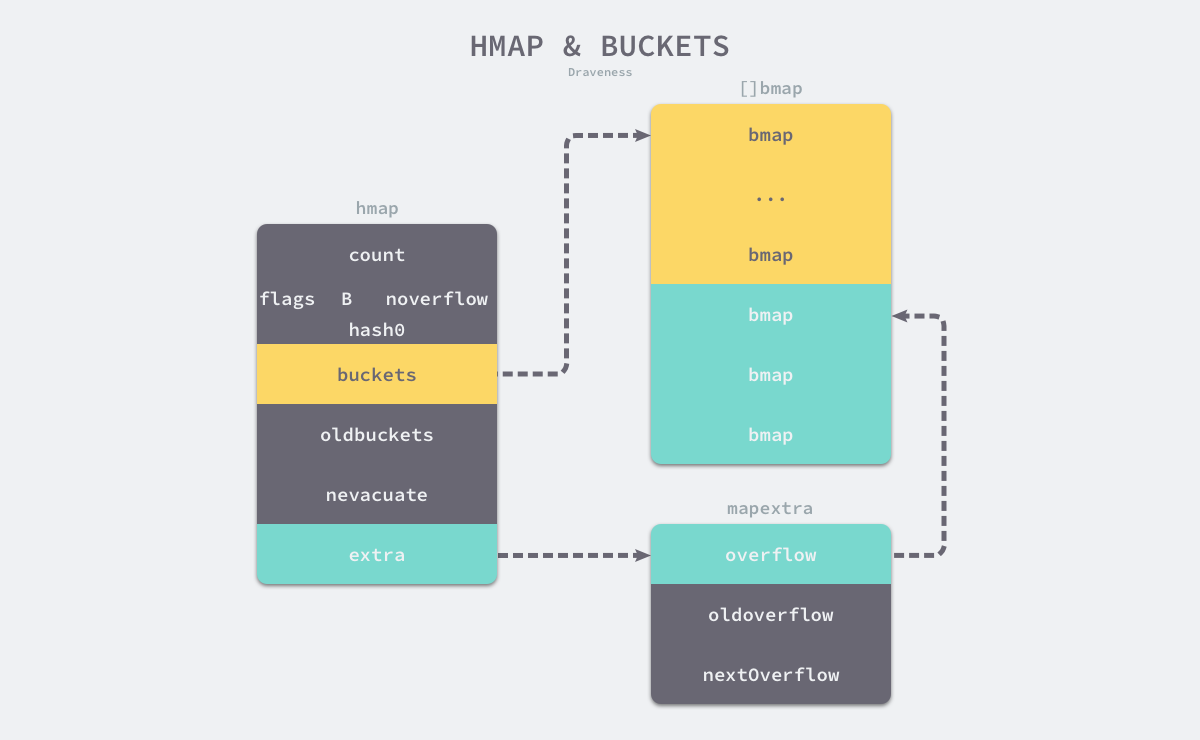
如上图所示哈希表 runtime.hmap 的桶是 runtime.bmap。每一个 runtime.bmap 都能存储 8 个键值对,当哈希表中存储的数据过多,单个桶已经装满时就会使用 extra.nextOverflow 中桶存储溢出的数据。
上述两种不同的桶在内存中是连续存储的,我们在这里将它们分别称为正常桶和溢出桶,上图中黄色的 runtime.bmap 就是正常桶,绿色的 runtime.bmap 是溢出桶
桶的结构体 runtime.bmap 在 Go 语言源代码中的定义只包含一个简单的 tophash 字段,tophash 存储了键的哈希的高 8 位,通过比较不同键的哈希的高 8 位可以减少访问键值对次数以提高性能?????:
1 | type bmap struct { |
初始化
1.字面量
目前的现代编程语言基本都支持使用字面量的方式初始化哈希,一般都会使用 key: value 的语法来表示键值对,Go 语言中也不例外:
1 | hash := map[string]int{ |
我们需要在初始化哈希时声明键值对的类型,这种使用字面量初始化的方式最终都会通过 cmd/compile/internal/gc.maplit 初始化,我们来分析一下该函数初始化哈希的过程:
1 | func maplit(n *Node, m *Node, init *Nodes) { |
当哈希表中的元素数量少于或者等于 25 个时,编译器会将字面量初始化的结构体转换成以下的代码,将所有的键值对一次加入到哈希表中:
1 | hash := make(map[string]int, 3) |
这种初始化的方式与的数组和切片几乎完全相同,由此看来集合类型的初始化在 Go 语言中有着相同的处理逻辑。
一旦哈希表中元素的数量超过了 25 个,编译器会创建两个数组分别存储键和值,这些键值对会通过如下所示的 for 循环加入哈希:
1 | hash := make(map[string]int, 26) |
这里展开的两个切片 vstatk 和 vstatv 还会被编辑器继续展开,具体的展开方式可以阅读上一节了解切片的初始化,不过无论使用哪种方法,使用字面量初始化的过程都会使用 Go 语言中的关键字 make 来创建新的哈希并通过最原始的 [] 语法向哈希追加元素。
2.运行时
当创建的哈希被分配到栈上并且其容量小于 BUCKETSIZE = 8 时,Go 语言在编译阶段会使用如下方式快速初始化哈希,这也是编译器对小容量的哈希做的优化:
除此之外都时调用 runtime.makemap进行创建
这个函数会按照下面的步骤执行:
- 计算哈希占用的内存是否溢出或者超出能分配的最大值;
- 调用
runtime.fastrand获取一个随机的哈希种子; - 根据传入的
hint计算出需要的最小需要的桶的数量; - 使用
runtime.makeBucketArray创建用于保存桶的数组;
runtime.makeBucketArray 会根据传入的 B 计算出的需要创建的桶数量并在内存中分配一片连续的空间用于存储数据:
- 当桶的数量小于 2^4 时,由于数据较少、使用溢出桶的可能性较低,会省略创建的过程以减少额外开销;
- 当桶的数量多于 2^4 时,会额外创建 2^(B-4)个溢出桶;
在正常情况下,正常桶和溢出桶在内存中的存储空间是连续的,只是被 runtime.hmap 中的不同字段引用,当溢出桶数量较多时会通过 runtime.newobject 创建新的溢出桶。
1 | // make(map[k]v, hint), hint即预分配大小 |
读写
哈希表作为一种数据结构,我们肯定要分析它的常见操作,首先就是读写操作的原理。哈希表的访问一般都是通过下标或者遍历进行的:
1 | _ = hash[key] |
这两种方式虽然都能读取哈希表的数据,但是使用的函数和底层原理完全不同。前者需要知道哈希的键并且一次只能获取单个键对应的值,而后者可以遍历哈希中的全部键值对,访问数据时也不需要预先知道哈希的键。
数据结构的写一般指的都是增加、删除和修改,增加和修改字段都使用索引和赋值语句,而删除字典中的数据需要使用关键字 delete:
1 | hash[key] = value |
访问
1 | v := hash[key] // => v := *mapaccess1(maptype, hash, &key) |
赋值语句左侧接受参数的个数会决定使用的运行时方法:
- 当接受一个参数时,会使用
runtime.mapaccess1,该函数仅会返回一个指向目标值的指针; - 当接受两个参数时,会使用
runtime.mapaccess2,除了返回目标值之外,它还会返回一个用于表示当前键对应的值是否存在的bool值:
runtime.mapaccess1 会先通过哈希表设置的哈希函数、种子获取当前键对应的哈希,再通过 runtime.bucketMask 和 runtime.add 拿到该键值对所在的桶序号和哈希高位的 8 位数字。
1 | func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
在 bucketloop 循环中,哈希会依次遍历正常桶和溢出桶中的数据,它会先比较哈希的高 8 位和桶中存储的 tophash,后比较传入的和桶中的值以加速数据的读写。用于选择桶序号的是哈希的最低几位,而用于加速访问的是哈希的高 8 位,这种设计能够减少同一个桶中有大量相等 tophash 的概率影响性能。
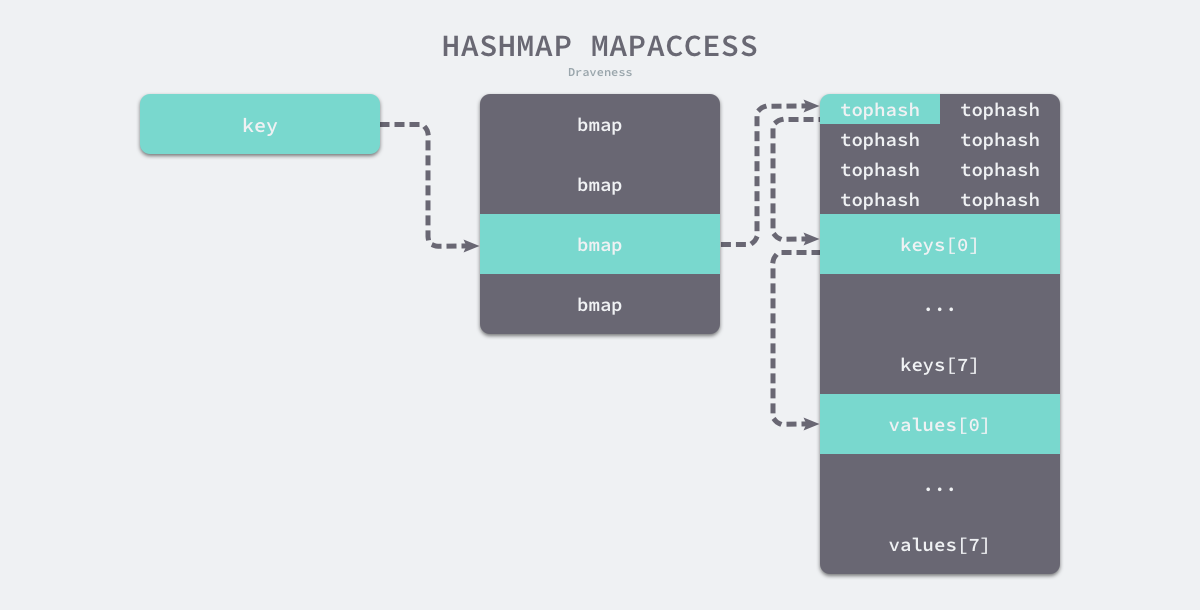
这种设计能够减少同一个桶中有大量相等
tophash的概率影响性能注:因为bmap结构中会先访问高8位的tophash 并和其之前计算得到的hashcode ,
如上图所示,每一个桶都是一整片的内存空间,当发现桶中的 tophash 与传入键的 tophash 匹配之后,我们会通过指针和偏移量获取哈希中存储的键 keys[0] 并与 key 比较,如果两者相同就会获取目标值的指针 values[0] 并返回。
另一个同样用于访问哈希表中数据的 runtime.mapaccess2 只是在 runtime.mapaccess1 的基础上多返回了一个标识键值对是否存在的 bool 值:
扩容
我们简单总结一下哈希表扩容的设计和原理,哈希在存储元素过多时会触发扩容操作,每次都会将桶的数量翻倍,扩容过程不是原子的,而是通过 runtime.growWork 增量触发的,在扩容期间访问哈希表时会使用旧桶,向哈希表写入数据时会触发旧桶元素的分流。除了这种正常的扩容之外,为了解决大量写入、删除造成的内存泄漏问题,哈希引入了 sameSizeGrow 这一机制,在出现较多溢出桶时会整理哈希的内存减少空间的占用。(等量扩容 创建等量的新通 此时溢出桶教多 但是没有触发增量扩容,表示可能由大量被删除的键值,此时空间排列不紧凑,等量扩容让空间更加紧凑,减少溢出桶的使用。)
1.负载因子大于6.5 触发增量扩容 翻倍
2.使用过多溢出桶 触发等量扩容 (常规桶数目 < 2^15 溢出桶超过常规桶)
根据触发的条件不同扩容的方式分成两种,如果这次扩容是溢出的桶太多导致的,那么这次扩容就是等量扩容
sameSizeGrow,sameSizeGrow是一种特殊情况下发生的扩容,当我们持续向哈希中插入数据并将它们全部删除时,如果哈希表中的数据量没有超过阈值,就会不断积累溢出桶造成缓慢的内存泄漏4。runtime: limit the number of map overflow buckets 引入了sameSizeGrow通过复用已有的哈希扩容机制解决该问题,一旦哈希中出现了过多的溢出桶,它会创建新桶保存数据,垃圾回收会清理老的溢出桶并释放内存5。
删除
如果想要删除哈希中的元素,就需要使用 Go 语言中的 delete 关键字,这个关键字的唯一作用就是将某一个键对应的元素从哈希表中删除,无论是该键对应的值是否存在,这个内建的函数都不会返回任何的结果。
总结
Go 语言使用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法。哈希在每一个桶中存储键对应哈希的前 8 位,当对哈希进行操作时,这些 tophash 就成为可以帮助哈希快速遍历桶中元素的缓存。
哈希表的每个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会存储到哈希的溢出桶中。随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容(负载因子大于6.5 数据量/桶数量),扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
说说map实现原理:
1.数组+链表形式存储 通过拉链法解决哈希碰撞。底层结构是hamp,B表示hash持有的桶数量 是2的倍数 桶结构是bmap,每个bmap都能存储8个k-v 有tophash字段比较高8位,overflow是溢出桶地址,当数据存储过多,就会使用溢出桶来存储数据。
2.每个桶数量要是2的倍数 因为计算hash 选桶 分散均匀
map底层创建时,会初始化一个hmap结构体,同时分配一个足够大的内存空间A。其中A的前段用于hash数组,A的后段预留给溢出的桶。于是hmap.buckets指向hash数组,即A的首地址;hmap.extra.nextOverflow初始时指向内存A中的后段,即hash数组结尾的下一个桶,也即第1个预留的溢出桶。所以当hash冲突需要使用到新的溢出桶时,会优先使用上述预留的溢出桶,hmap.extra.nextOverflow依次往后偏移直到用完所有的溢出桶,才有可能会申请新的溢出桶空间。
Golang Map实现(一) - Go语言中文网 - Golang中文社区 (studygolang.com)
go专家编程系列(4)常见数据结构 map_EINTR的博客-CSDN博客
(60条消息) Go map底层原理(哈希表)_王致列的博客-CSDN博客
深入理解 Go map:初始化和访问元素 (eddycjy.com)
go map数据结构和源码详解 - Jo_ZSM - 博客园 (cnblogs.com)
疑问
1.为什么哈希表中桶的数量都 2 的倍数?
2.为什么比较不同键的哈希的高 8 位可以减少访问键值对次数以提高性能?
3.使用溢出桶怎么减少扩容次数?
4.若hash冲突了 tophash 怎么存储?
5.为什么tophash是8位 而不是其他位数?(也就是k-v为什么是8个)
6.为什么key-value 分开存储?
7.低8位和高8位 key hash
1.为什么哈希表中桶的数量都 2 的倍数?
从键值的存储流程开始,当一个键值对来了 自然需要存储到一个桶中,然后将Key()通过Hash()处理一下得到hash值。现在要利用这个hash值从m个桶中选择一个,桶的编号[0,m-1]
取模法
hash%m
与运算法
hash & (m-1) 增加运算速度
m是2的倍数时候 才等价 可以 均匀散列
如果m = 2 二进制是10 则 m-1 二进制是 1
m = 4 二进制是100 则m-1 二进制是 11
m = 8 二进制是1000 则m-1 二进制是 111
这样2^n -1 得出的结果除最高位必定是1111
这样和hashcode计算时就仅仅由hashcode决定值 而不会形成”缺口”
如果不是2的倍数 例如 m =9 则 二进制是 10001 无论hashcode是多少 计算得到的值永远在第一个桶和最后一个桶 其余桶永远不会由数据。
所以想要使用与运算法就要限制桶的个数 m 必须是2 的整数次幂,这样 m 的二进制表示一定只有一位为1,(m-1) 就是
除了最高为其他均为 1 ,避免计算hash 只会分配到固定的几个桶 导致一些桶绝对不会被选中的情况
如果之后有其他键值对也选择了同一个桶,就是发生了哈希冲突,解决方案一般是 开放地址法 和 拉链法
2倍这个数字贯穿了map的很多部分
2.为什么比较不同键的哈希的高 8 位可以减少访问键值对次数以提高性能?
解答:当tophash对应的K/V被使用时,存的是key的哈希值的高8位;当tophash对应的K/V未被使用时,存的是K/V对应位置的状态。
![[外链图片转存失败(img-VCPzgZ2R-1564057589001)(./1560938034341.png)]](/./../images/tophash.png)
下面是map源码中对tophash状态值的定义。
1 | emptyRest = 0 |
当tophash[i] < 5时,表示存的是状态;
当tophash[i] >= 5时,表示存的是哈希值;
那么问题来了,如果key的哈希值高8位小于minTopHash时,这时候怎么区分是存的状态还是哈希值?
1 | func tophash(hash uintptr) uint8 { |
直接看上面源码,第3-5行可以知道,当计算的哈希值小于minTopHash时,会直接在原有哈希值基础上加上minTopHash,确保哈希值一定大于minTopHash。
5
- 为啥bucket 一次要存8个kv,而不是一个kv放一个bucket,然后链地址法做处理就OK了 据我分析,有几点原因: a, 一次分配8个kv的空间,可以减少内存的分配频次; b,减少了overflow指针的内存占用,比如说8个kv,采用一个一个存储的话,需要8 * 8B (64位机) = 64B的数据存下一个的地址,而采用go实现的这种方式,只需要 8B + 8B (bmap的大小) = 16B 的数据就可以了。
- 为啥需要用tophash 一般的hash 实现逻辑是直接和key比较,如果比较成功,这找到相应key的数据。但是这里用到了tophash,好处是可以减少key的比较成本(毕竟key 不一定都是整数形式存在的)
- 为啥是8个 8 * 8B = 64B 整好是64位机的一个最小寻址空间,不过可以通过修改源码自定义吧。
keys和values为分开存储的,因为key和value可能是不同类型,比如map[int64]int8
此时kv/kv/kv 形式由于内存对其将浪费7字节, kkkvvv 就可以节省空间
8
- 根据低八位计算得到 bucket 的内存地址,并判断是否正在扩容,若正在扩容中则先迁移再接着处理
- 计算并得到 bucket 的 bmap 指针地址,计算 key hash 高八位用于查找 Key
字符串
拼接问题
cmd/compile/internal/gc.addstr 能帮助我们在编译期间选择合适的函数对字符串进行拼接,该函数会根据带拼接的字符串数量选择不同的逻辑:
- 如果小于或者等于 5 个,那么会调用
concatstring{2,3,4,5}等一系列函数; - 如果超过 5 个,那么会选择
runtime.concatstrings传入一个数组切片;
其实无论使用 concatstring{2,3,4,5} 中的哪一个,最终都会调用 runtime.concatstrings,它会先对遍历传入的切片参数,再过滤空字符串并计算拼接后字符串的长度。
字符串在 Go 语言中是不可变类型,占用内存大小是固定的,当使用 + 拼接 2 个字符串时,生成一个新的字符串,那么就需要开辟一段新的空间,新空间的大小是原来两个字符串的大小之和。拼接第三个字符串时,再开辟一段新空间,新空间大小是三个字符串大小之和,以此类推。假设一个字符串大小为 10 byte,拼接 1w 次,需要申请的内存大小为:
1 | 10 + 2 * 10 + 3 * 10 + ... + 10000 * 10 byte = 500 MB |
而 strings.Builder,bytes.Buffer,包括切片 []byte 的内存是以倍数申请的。例如,初始大小为 0,当第一次写入大小为 10 byte 的字符串时,则会申请大小为 16 byte 的内存(恰好大于 10 byte 的 2 的指数),第二次写入 10 byte 时,内存不够,则申请 32 byte 的内存,第三次写入内存足够,则不申请新的,以此类推。在实际过程中,超过一定大小,比如 2048 byte 后,申请策略上会有些许调整
类型转换
[]byte转string
从字节数组到字符串的转换需要使用 runtime.slicebytetostring 函数,例如:string(bytes)
他会根据传入的缓冲区大小决定是否需要为新字符串分配一片内存空间,runtime.stringStructOf 会将传入的字符串指针转换成 runtime.stringStruct 结构体指针,然后设置结构体持有的字符串指针 str 和长度 len,最后通过 runtime.memmove 将原 []byte 中的字节全部复制到新的内存空间中。
字符串转[]byte
当我们想要将字符串转换成 []byte 类型时,需要使用 runtime.stringtoslicebyte 函数,该函数的实现非常容易理解:
1 | func stringtoslicebyte(buf *tmpBuf, s string) []byte { |
上述函数会根据是否传入缓冲区做出不同的处理:
- 当传入缓冲区时,它会使用传入的缓冲区存储
[]byte; - 当没有传入缓冲区时,运行时会调用
runtime.rawbyteslice创建新的字节切片并将字符串中的内容拷贝过去;
字符串和 []byte 中的内容虽然一样,但是字符串的内容是只读的,我们不能通过下标或者其他形式改变其中的数据,而 []byte 中的内容是可以读写的。不过无论从哪种类型转换到另一种都需要拷贝数据,而内存拷贝的性能损耗会随着字符串和 []byte 长度的增长而增长。
函数调用
C语言
我们可以将本节的发现和分析简单总结成 — 当我们在 x86_64 的机器上使用 C 语言中调用函数时,参数都是通过寄存器和栈传递的,其中:
- 六个以及六个以下的参数会按照顺序分别使用 edi、esi、edx、ecx、r8d 和 r9d 六个寄存器传递;
- 六个以上的参数会使用栈传递,函数的参数会以从右到左的顺序依次存入栈中;
而函数的返回值是通过 eax 寄存器进行传递的,由于只使用一个寄存器存储返回值,所以 C 语言的函数不能同时返回多个值。
Go语言
通过分析 Go 语言编译后的汇编指令,我们发现 Go 语言使用栈传递参数和接收返回值,所以它只需要在栈上多分配一些内存就可以返回多个值。
对比
C 语言和 Go 语言在设计函数的调用惯例时选择了不同的实现。C 语言同时使用寄存器和栈传递参数,使用 eax 寄存器传递返回值;而 Go 语言使用栈传递参数和返回值。我们可以对比一下这两种设计的优点和缺点:
- C 语言的方式能够极大地减少函数调用的额外开销,但是也增加了实现的复杂度;
- CPU 访问栈的开销比访问寄存器高几十倍3;
- 需要单独处理函数参数过多的情况;
- Go 语言的方式能够降低实现的复杂度并支持多返回值,但是牺牲了函数调用的性能;
- 不需要考虑超过寄存器数量的参数应该如何传递;
- 不需要考虑不同架构上的寄存器差异;
- 函数入参和出参的内存空间需要在栈上进行分配;
Go 语言使用栈作为参数和返回值传递的方法是综合考虑后的设计,选择这种设计意味着编译器会更加简单、更容易维护。
参数传递
所以能得出如下结论:Go 语言的整型和数组类型都是值传递的,也就是在调用函数时会对内容进行拷贝。需要注意的是如果当前数组的大小非常的大,这种传值的方式会对性能造成比较大的影响。
结构体和指针
接下来我们继续分析 Go 语言另外两种常见类型 — 结构体和指针。下面这段代码中定义了一个结构体 MyStruct 以及接受两个参数的 myFunction 方法:
1 | type MyStruct struct { |
Go
从上述运行的结果我们可以得出如下结论:
- 传递结构体时:会拷贝结构体中的全部内容;
- 传递结构体指针时:会拷贝结构体指针;
修改结构体指针是改变了指针指向的结构体,b.i 可以被理解成 (*b).i,也就是我们先获取指针 b 背后的结构体,再修改结构体的成员变量
将指针作为参数传入某个函数时,函数内部会复制指针,也就是会同时出现两个指针指向原有的内存空间,所以 Go 语言中传指针也是传值。
当我们验证了 Go 语言中大多数常见的数据结构之后,其实能够推测出 Go 语言在传递参数时使用了传值的方式,
接收方收到参数时会对这些参数进行复制;了解到这一点之后,在传递数组或者内存占用非常大的结构体时,我们
应该尽量使用指针作为参数类型来避免发生数据拷贝进而影响性能。
Go 通过栈传递函数的参数和返回值,在调用函数之前会在栈上为返回值分配合适的内存空间,随后将入参从右到左按顺序压栈并拷贝参数,返回值会被存储到调用方预留好的栈空间上,我们可以简单总结出以下几条规则:
- 通过堆栈传递参数,入栈的顺序是从右到左,而参数的计算是从左到右;
- 函数返回值通过堆栈传递并由调用者预先分配内存空间;
- 调用函数时都是传值,接收方会对入参进行复制再计算;
接口
interface{} 类型是一种特殊的类型 它可以装下其余类型任何值,它不属于其余任何一种类型。
interface表示一种类型,可以接收任何实现了interface当中规定的方法的类型的值。当我们定义inteface{}的时候,其实是定义了空的interface,相当于不需要实现任何方法的空interface,所以任何类型都可以接收,这也就是它成为万能类型的原因。
一个接口
1 | type error interface { |
如果一个类型需要实现 error 接口,那么它只需要实现 Error() string 方法,下面的 RPCError 结构体就是 error 接口的一个实现:
1 | type RPCError struct { |
使用&对结构体进只有当结构体实例化时,才会真正地分配内存。也就是必须实例化后才能使用结构体的字段行取地址操作相当于对该结构体类型进行了一次new实例化操作
1 | func main() { |
Go 语言中接口的实现都是隐式的
Go 语言实现接口的方式与 Java 完全不同:
- 在 Java 中:实现接口需要显式地声明接口并实现所有方法;
- 在 Go 中:实现接口的所有方法就隐式地实现了接口;
我们使用上述 RPCError 结构体时并不关心它实现了哪些接口,Go 语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查,
接口的底层数据结构
Go 语言根据接口类型是否包含一组方法将接口类型分成了两类:
- 使用
runtime.iface结构体表示包含方法的接口 - 使用
runtime.eface结构体表示不包含任何方法的interface{}类型;
动态派发(Dynamic dispatch)是在运行期间选择具体多态操作(方法或者函数)执行的过程,它是面向对象语言中的常见特性6。Go 语言虽然不是严格意义上的面向对象语言,但是接口的引入为它带来了动态派发这一特性,调用接口类型的方法时,如果编译期间不能确认接口的类型,Go 语言会在运行期间决定具体调用该方法的哪个实现。
在如下所示的代码中,main 函数调用了两次 Quack 方法:
- 第一次以
Duck接口类型的身份调用,调用时需要经过运行时的动态派发; - 第二次以
*Cat具体类型的身份调用,编译期就会确定调用的函数:
1 | func main() { |
| 直接调用 | 动态派发 | |
|---|---|---|
| 指针 | ~3.03ns | ~3.58ns |
| 结构体 | ~3.09ns | ~6.98ns |
表 4-2 直接调用和动态派发的性能对比
从上述表格我们可以看到使用结构体实现接口带来的开销会大于使用指针实现,而动态派发在结构体上的表现非常差,这也提醒我们应当尽量避免使用结构体类型实现接口。
使用结构体带来的巨大性能差异不只是接口带来的问题,带来性能问题主要因为 Go 语言在函数调用时是传值的,动态派发的过程只是放大了参数拷贝带来的影响。
[译]Go 和 interface 探究 (xargin.com)
反射
运行时反射是程序在运行期间检查其自身结构的一种方式
反射作为一种元编程方式可以减少重复代码
Go 语言反射的三大法则3,其中包括:
- 从
interface{}变量可以反射出反射对象; - 从反射对象可以获取
interface{}变量; - 要修改反射对象,其值必须可设置;
第一法则
我们可以通过以下例子简单介绍它们的作用,reflect.TypeOf 获取了变量 author 的类型,reflect.ValueOf 获取了变量的值 draven。如果我们知道了一个变量的类型和值,那么就意味着我们知道了这个变量的全部信息。
1 | package main |
第二法则
反射的第二法则是我们可以从反射对象可以获取 interface{} 变量。既然能够将接口类型的变量转换成反射对象,那么一定需要其他方法将反射对象还原成接口类型的变量,reflect 中的 reflect.Value.Interface 就能完成这项工作:
第三法则
由于 Go 语言的函数调用都是传值的,所以我们得到的反射对象跟最开始的变量没有任何关系,那么直接修改反射对象无法改变原始变量,程序为了防止错误就会崩溃。
想要修改原变量只能使用如下的方法:
1 | func main() { |
- 调用
reflect.ValueOf获取变量指针; - 调用
reflect.Value.Elem获取指针指向的变量; - 调用
reflect.Value.SetInt更新变量的值:
由于 Go 语言的函数调用都是值传递的,所以我们只能只能用迂回的方式改变原变量:先获取指针对应的 reflect.Value,再通过 reflect.Value.Elem 方法得到可以被设置的变量,我们可以通过下面的代码理解这个过程:
1 | func main() { |
如果不能直接操作 i 变量修改其持有的值,我们就只能获取 i 变量所在地址并使用 *v 修改所在地址中存储的整数。
空interface{}结构体
1 | type emptyInterface struct { |
更新变量
当我们想要更新 reflect.Value 时,就需要调用 reflect.Value.Set 更新反射对象
reflect.Value.Set 会调用 reflect.Value.assignTo 并返回一个新的反射对象,这个返回的反射对象指针会
直接覆盖原反射变量。
1 | func (v Value) assignTo(context string, dst *rtype, target unsafe.Pointer) Value { |
reflect.Value.assignTo 会根据当前和被设置的反射对象类型创建一个新的 reflect.Value 结构体:
- 如果两个反射对象的类型是可以被直接替换,就会直接返回目标反射对象;
- 如果当前反射对象是接口并且目标对象实现了接口,就会把目标对象简单包装成接口值;
在变量更新的过程中,reflect.Value.assignTo 返回的 reflect.Value 中的指针会覆盖当前反射对象中的指针实现变量的更新。
接口检查
reflect 包还为我们提供了 reflect.rtype.Implements 方法可以用于判断某些类型是否遵循特定的接口。在 Go 语言中获取结构体的反射类型 reflect.Type 还是比较容易的,但是想要获得接口类型需要通过以下方式:
1 | reflect.TypeOf((*<interface>)(nil)).Elem() |
我们通过一个例子在介绍如何判断一个类型是否实现了某个接口。假设我们需要判断如下代码中的 CustomError 是否实现了 Go 语言标准库中的 error 接口:
1 | type CustomError struct{} |
Go
上述代码的运行结果正如我们在接口一节中介绍的:
CustomError类型并没有实现error接口;*CustomError指针类型实现了error接口;
判断原理
1.首先reflect.rtype.Implements 会检查传入的类型是不是接口,如果不是接口会直接中止程序
2.判断接口中包含的方法,若不包含方法就返回true,否则遍历,
动态方法调用
作为一门静态语言,如果我们想要通过 reflect 包利用反射在运行期间执行方法不是一件容易的事情,下面的十几行代码就使用反射来执行 Add(0, 1) 函数:
1 | func Add(a, b int) int { return a + b } |
- 通过
reflect.ValueOf获取函数Add对应的反射对象; - 调用
reflect.rtype.NumIn获取函数的入参个数; - 多次调用
reflect.ValueOf函数逐一设置argv数组中的各个参数; - 调用反射对象
Add的reflect.Value.Call方法并传入参数列表; - 获取返回值数组、验证数组的长度以及类型并打印其中的数据;
使用反射来调用方法非常复杂,原本只需要一行代码就能完成的工作,现在需要十几行代码才能完成,但这也是在静态语言中使用动态特性需要付出的成本。
reflect.Value.Call 在编译期间链接到 reflect.reflectcall 这个用汇编实现的函数 比较复杂
Go 语言的 reflect 包为我们提供了多种能力,包括如何使用反射来动态修改变量、判断类型是否实现了某些接口以及动态调用方法等功能
for-range
与简单的经典循环相比,范围循环在 Go 语言中更常见、实现也更复杂。这种循环同时使用 for 和 range 两个关键字,编译器会在编译期间将所有 for-range 循环变成经典循环。从编译器的视角来看,就是将 ORANGE 类型的节点转换成 OFOR 节点
循环永动机
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组赋值给一个新变量 ha,在赋值的过程中就发生了拷贝,而我们又通过 len 关键字预先获取了切片的长度,所以在循环中追加新的元素也不会改变循环执行的次数,这也就解释了循环永动机一节提到的现象。
而遇到这种同时遍历索引和元素的 range 循环时,Go 语言会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2 会在每一次迭代被重新赋值而覆盖,赋值时也会触发拷贝。
1 | func main() { |
因为在循环中获取返回变量的地址都完全相同,所以会发生神奇的指针一节中的现象。因此当我们想要访问数组中元素所在的地址时,不应该直接获取 range 返回的变量地址 &v2,而应该使用 &a[index] 这种形式。
for range陷阱
而遇到这种同时遍历索引和元素的 range 循环时,Go 语言会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2 会在每一次迭代被重新赋值而覆盖,赋值时也会触发拷贝。
1 | func main() { |
因为在循环中获取返回变量的地址都完全相同(每次取得是V2变量得地址 正确应该取arr[i]得地址),所以会发生神奇的指针一节中的现象。因此当我们想要访问数组中元素所在的地址时,不应该直接获取 range 返回的变量地址 &v2,而应该使用 &a[index] 这种形式。
通道
使用 range 遍历 Channel 也是比较常见的做法,一个形如 for v := range ch {} 的语句最终会被转换成如下的格式:
1 | ha := a |
这里的代码可能与编译器生成的稍微有一些出入,但是结构和效果是完全相同的。该循环会使用 <-ch 从管道中取出等待处理的值,这个操作会调用 runtime.chanrecv2 并阻塞当前的协程,当 runtime.chanrecv2 返回时会根据布尔值 hb 判断当前的值是否存在:
- 如果不存在当前值,意味着当前的管道已经被关闭;
- 如果存在当前值,会为
v1赋值并清除hv1变量中的数据,然后重新陷入阻塞等待新数据;
select
例子
select 是与 switch 相似的控制结构,与 switch 不同的是,select 中虽然也有多个 case,但是这些 case 中的表达式必须都是 Channel 的收发操作。下面的代码就展示了一个包含 Channel 收发操作的 select 结构:
1 | func fibonacci(c, quit chan int) { |
上述控制结构会等待 c <- x 或者 <-quit 两个表达式中任意一个返回。无论哪一个表达式返回都会立刻执行 case 中的代码,当 select 中的两个 case 同时被触发时,会随机执行其中的一个。
现象
当我们在 Go 语言中使用 select 控制结构时,会遇到两个有趣的现象:
select能在 Channel 上进行非阻塞的收发操作;select在遇到多个 Channel 同时响应时,会随机执行一种情况;(避免按顺序的饥饿问题发生)
我们来深入了解具体场景并分析这两个现象背后的设计原理。
编译器在中间代码生成期间会根据 select 中 case 的不同对控制语句进行优化,这一过程都发生在 cmd/compile/internal/gc.walkselectcases 函数中,我们在这里会分四种情况介绍处理的过程和结果:
select不存在任何的case;select只存在一个case;select存在两个case,其中一个case是default;select存在多个case;
上述四种情况不仅会涉及编译器的重写和优化,还会涉及 Go 语言的运行时机制,我们会从编译期间和运行时两个角度分析上述情况。
直接阻塞
select 不存在任何case时直接阻塞当前 Goroutine,导致 Goroutine 进入无法被唤醒的永久休眠状态。
2.单一管道
如果当前的 select 条件只包含一个 case,那么编译器会将 select 改写成 if 条件语句。下面对比了改写前后的代码:
1 | // 改写前 |
cmd/compile/internal/gc.walkselectcases 在处理单操作 select 语句时,会根据 Channel 的收发情况生成不同的语句。当 case 中的 Channel 是空指针时,会直接挂起当前 Goroutine 并陷入永久休眠。
我们简单总结一下 select 结构的执行过程与实现原理,首先在编译期间,Go 语言会对 select 语句进行优化,它会根据 select 中 case 的不同选择不同的优化路径:
空的
select语句会被转换成调用runtime.block直接挂起当前 Goroutine;如果
select语句中只包含一个case编译器会将其转换成if ch == nil { block }; n;表达式;
- 首先判断操作的 Channel 是不是空的;
- 然后执行
case结构中的内容;
如果
select语句中只包含两个case并且其中一个是default,那么会使用runtime.selectnbrecv和runtime.selectnbsend非阻塞地执行收发操作;在默认情况下会通过
runtime.selectgo获取执行case的索引,并通过多个if语句执行对应case中的代码;
在编译器已经对 select 语句进行优化之后,Go 语言会在运行时执行编译期间展开的 runtime.selectgo 函数,该函数会按照以下的流程执行:
随机生成一个遍历的轮询顺序
pollOrder并根据 Channel 地址生成锁定顺序lockOrder;根据
pollOrder遍历所有的case查看是否有可以立刻处理的 Channel;
- 如果存在,直接获取
case对应的索引并返回; - 如果不存在,创建
runtime.sudog结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列,并调用runtime.gopark挂起当前 Goroutine 等待调度器的唤醒;
- 如果存在,直接获取
当调度器唤醒当前 Goroutine 时,会再次按照
lockOrder遍历所有的case,从中查找需要被处理的runtime.sudog对应的索引;
select 关键字是 Go 语言特有的控制结构,它的实现原理比较复杂,需要编译器和运行时函数的通力合作。
defer
我们在 Go 语言中使用 defer 时会遇到两个常见问题,这里会介绍具体的场景并分析这两个现象背后的设计原理:
defer关键字的调用时机以及多次调用defer时执行顺序是如何确定的;defer关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果;
1.作用域
利用defer倒序输出
1 | func main() { |
运行上述代码会倒序执行传入 defer 关键字的所有表达式,因为最后一次调用 defer 时传入了 fmt.Println(4),所以这段代码会优先打印 4。
1 | func main() { |
从上述代码的输出我们会发现,defer 传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回之前被调用。
2.参数计算
[深入 Go 语言 defer 实现原理 - 腾讯云开发者社区-腾讯云 (tencent.com)](https://cloud.tencent.com/developer/article/1820164#:~:text=defer 声明时会先计算确定参数的值 func a() { i %3A%3D 0,在这个例子中,变量 i 在 defer 被调用的时候就已经确定了,而不是在 defer 执行的时候,所以上面的语句输出的是 0。)
Go 语言中所有的函数调用都是传值的,虽然 defer 是关键字,但是也继承了这个特性。假设我们想要计算 main 函数运行的时间,可能会写出以下的代码:
1 | func main() { |
然而上述代码的运行结果并不符合我们的预期,这个现象背后的原因是什么呢?经过分析,我们会发现调用 defer 关键字会立刻拷贝函数中引用的外部参数,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的,最终导致上述代码输出 0s。
想要解决这个问题的方法非常简单,我们只需要向 defer 关键字传入匿名函数:
1 | func main() { |
虽然调用 defer 关键字时也使用值传递,但是因为拷贝的是函数指针,所以 time.Since(startedAt) 会在 main 函数返回前调用并打印出符合预期的结果。
defer 声明时会先计算确定参数的值
1 | func a() { |
在这个例子中,变量 i 在 defer被调用的时候就已经确定了,而不是在 defer执行的时候,所以上面的语句输出的是 0。
defer 可以修改有名返回值函数的返回值
如同官方所说:
For instance, if the deferred function is a function literal and the surrounding function has named result parameters that are in scope within the literal, the deferred function may access and modify the result parameters before they are returned.
上面所说的是,如果一个被defer调用的函数是一个 function literal,也就是说是闭包或者匿名函数,并且调用 defer的函数时一个有名返回值(named result parameters)的函数,那么 defer 可以直接访问有名返回值并进行修改的。
例子如下:
1 | // f returns 42 |
但是需要注意的是,只能修改有名返回值(named result parameters)函数,匿名返回值函数是无法修改的,如下:
1 | // f returns 100 |
因为匿名返回值函数是在return执行时被声明,因此在defer语句中只能访问有名返回值函数,而不能直接访问匿名返回值函数。
derfer与return的执行顺序
Golang语言中函数的return不是原子操作,在底层是分为两步来执行
1.返回值 赋值保存 如果返回值为匿名格式,那么将用一个临时变量保存该返回值
2.真正的RET返回
如果函数中存在defer 那么那么 执行顺序时机是在第一步和第二步之间即
1.返回值 赋值保存 如果返回值为匿名格式,那么将用一个临时变量保存该返回值
2.defer执行
3.真正的RET返回
我们在本节前面提到的两个现象在这里也可以解释清楚了:
后调用的
defer函数会先执行:
- 后调用的
defer函数会被追加到 Goroutine_defer链表的最前面; - 运行
runtime._defer时是从前到后依次执行;
- 后调用的
函数的参数会被预先计算;
- 调用
runtime.deferproc函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算;
- 调用
panic 与 recover
Go 语言中两个经常成对出现的两个关键字 — panic 和 recover。这两个关键字与上一节提到的 defer 有紧密的联系,它们都是 Go 语言中的内置函数,也提供了互补的功能。
panic能够改变程序的控制流,调用panic后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行调用方的defer;recover可以中止panic造成的程序崩溃。它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用;
现象
我们先通过几个例子了解一下使用 panic 和 recover 关键字时遇到的现象,部分现象也与上一节分析的 defer 关键字有关:
panic只会触发当前 Goroutine 的defer;recover只有在defer中调用才会生效;panic允许在defer中嵌套多次调用;
1.跨协程失效
首先要介绍的现象是 panic 只会触发当前 Goroutine 的延迟函数调用,我们可以通过如下所示的代码了解该现象:
1 | func main() { |
当我们运行这段代码时会发现 main 函数中的 defer 语句并没有执行,执行的只有当前 Goroutine 中的 defer。
前面我们曾经介绍过 defer 关键字对应的 runtime.deferproc 会将延迟调用函数与调用方所在 Goroutine 进行关联。所以当程序发生崩溃时只会调用当前 Goroutine 的延迟调用函数也是非常合理的
2.失效的崩溃恢复
初学 Go 语言的读者可能会写出下面的代码,在主程序中调用 recover 试图中止程序的崩溃,但是从运行的结果中我们也能看出,下面的程序没有正常退出。
1 | func main() { |
仔细分析一下这个过程就能理解这种现象背后的原因,recover 只有在发生 panic 之后调用才会生效。然而在上面的控制流中,recover 是在 panic 之前调用的,并不满足生效的条件,所以我们需要在 defer 中使用 recover 关键字。
make和new
当我们想要在 Go 语言中初始化一个结构时,可能会用到两个不同的关键字 — make 和 new。因为它们的功能相似,所以初学者可能会对这两个关键字的作用感到困惑1,但是它们两者能够初始化的变量却有较大的不同。
我们在代码中往往都会使用如下所示的语句初始化这三类基本类型,这三个语句分别返回了不同类型的数据结构:
1 | slice := make([]int, 0, 100) |
slice是一个包含data、cap和len的结构体reflect.SliceHeader;hash是一个指向runtime.hmap结构体的指针;ch是一个指向runtime.hchan结构体的指针;
相比与复杂的 make 关键字,new 的功能就简单多了,它只能接收类型作为参数然后返回一个指向该类型的指针:
1 | i := new(int) |
上述代码片段中的两种不同初始化方法是等价的,它们都会创建一个指向 int 零值的指针。
上下文Context
上下文 context.Context Go 语言中用来设置截止日期、同步信号,传递请求相关值的结构体。上下文与 Goroutine 有比较密切的关系,是 Go 语言中独特的设计
设计原理
在 Goroutine 构成的树形结构中对信号进行同步以减少计算资源的浪费是 context.Context 的最大作用。Go 服务的每一个请求都是通过单独的 Goroutine 处理的2,HTTP/RPC 请求的处理器会启动新的 Goroutine 访问数据库和其他服务。
如下图所示,我们可能会创建多个 Goroutine 来处理一次请求,而 context.Context 的作用是在不同 Goroutine 之间同步请求特定数据、取消信号以及处理请求的截止日期。
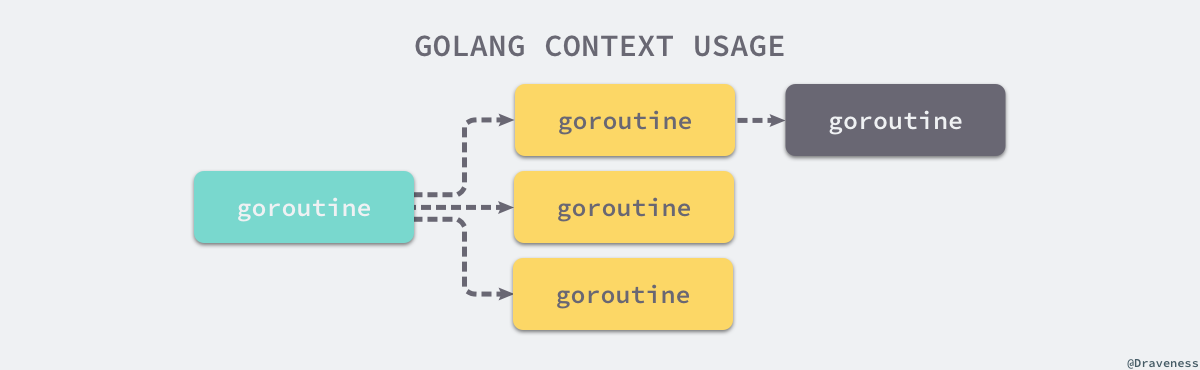
每一个 context.Context 都会从最顶层的 Goroutine 一层一层传递到最下层。context.Context 可以在上层 Goroutine 执行出现错误时,将信号及时同步给下层。
当最上层的 Goroutine 因为某些原因执行失败时,下层的 Goroutine 由于没有接收到这个信号所以会继续工作;但是当我们正确地使用 context.Context 时,就可以在下层及时停掉无用的工作以减少额外资源的消耗
context.Context 是 Go 语言在 1.7 版本中引入标准库的接口1,该接口定义了四个需要实现的方法,其中包括:
Deadline— 返回context.Context被取消的时间,也就是完成工作的截止日期;Done— 返回一个 Channel,这个 Channel 会在当前工作完成或者上下文被取消后关闭,多次调用Done方法会返回同一个 Channel;Err— 返回context.Context结束的原因,它只会在Done方法对应的 Channel 关闭时返回非空的值;- 如果
context.Context被取消,会返回Canceled错误; - 如果
context.Context超时,会返回DeadlineExceeded错误;
- 如果
Value— 从context.Context中获取键对应的值,对于同一个上下文来说,多次调用Value并传入相同的Key会返回相同的结果,该方法可以用来传递请求特定的数据;
1 | type Context interface { |
context 包中提供的 context.Background、context.TODO、context.WithDeadline 和 context.WithValue 函数会返回实现该接口的私有结构体,我们会在后面详细介绍它们的工作原理。
Background 与 TODO
context 包提供了 Background 方法和 TODO 方法,用来返回一个emptyContext
我们可以用这个 空的 Context 作为 goroutine 的root 节点(如果把整个 goroutine 的关系看作 树状)
例子
我们可以通过一个代码片段了解 context.Context 是如何对信号进行同步的。在这段代码中,我们创建了一个过期时间为 1s 的上下文,并向上下文传入 handle 函数,该方法会使用 500ms 的时间处理传入的请求:
1 | func main() { |
因为过期时间大于处理时间,所以我们有足够的时间处理该请求,运行上述代码会打印出下面的内容:
1 | $ go run context.go |
handle 函数没有进入超时的 select 分支,但是 main 函数的 select 却会等待 context.Context 超时并打印出 main context deadline exceeded。
如果我们将处理请求时间增加至 1500ms,整个程序都会因为上下文的过期而被中止,:
1 | $ go run context.go |
相信这两个例子能够帮助各位读者理解 context.Context 的使用方法和设计原理 — 多个 Goroutine 同时订阅 ctx.Done() 管道中的消息****,一旦接收到取消信号就立刻停止当前正在执行的工作。
用法
withvalue
https://blog.csdn.net/tang_yu_mac/article/details/122249280
1 | package main |
golang之context使用_云原生手记的博客-CSDN博客_withdeadline withtimeout区别
同步原语与锁
Mutex
Go 语言的 sync.Mutex 由两个字段 state 和 sema 组成。其中 state 表示当前互斥锁的状态,而 sema 是用于控制锁状态的信号量。
1 | type Mutex struct { |
上述两个加起来只占 8 字节空间的结构体表示了 Go 语言中的互斥锁。
我们已经从多个方面分析了互斥锁 sync.Mutex 的实现原理,这里我们从加锁和解锁两个方面总结注意事项。
互斥锁的加锁过程比较复杂,它涉及自旋、信号量以及调度等概念:
- 如果互斥锁处于初始化状态,会通过置位
mutexLocked加锁; - 如果互斥锁处于
mutexLocked状态并且在普通模式下工作,会进入自旋,执行 30 次PAUSE指令消耗 CPU 时间等待锁的释放; - 如果当前 Goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式;
- 互斥锁在正常情况下会通过
runtime.sync_runtime_SemacquireMutex将尝试获取锁的 Goroutine 切换至休眠状态,等待锁的持有者唤醒; - 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,那么它会将互斥锁切换回正常模式;
互斥锁的解锁过程与之相比就比较简单,其代码行数不多、逻辑清晰,也比较容易理解:
- 当互斥锁已经被解锁时,调用
sync.Mutex.Unlock会直接抛出异常; - 当互斥锁处于饥饿模式时,将锁的所有权交给队列中的下一个等待者,等待者会负责设置
mutexLocked标志位; - 当互斥锁处于普通模式时,如果没有 Goroutine 等待锁的释放或者已经有被唤醒的 Goroutine 获得了锁,会直接返回;在其他情况下会通过
sync.runtime_Semrelease唤醒对应的 Goroutine;
RWMutex
读写互斥锁 sync.RWMutex 是细粒度的互斥锁,它不限制资源的并发读,但是读写、写写操作无法并行执行。
| 读 | 写 | |
|---|---|---|
| 读 | Y | N |
| 写 | N | N |
表 6-1 RWMutex 的读写并发
常见服务的资源读写比例会非常高,因为大多数的读请求之间不会相互影响,所以我们可以分离读写操作,以此来提高服务的性能。
读写锁是针对于读写操作的互斥锁。它与普通的互斥锁最大的不同就是,它可以分别针对读操作和写操作进行锁定和解锁操作。读写锁遵循的访问控制规则与互斥锁有所不同。在读写锁管辖的范围内,它允许任意个读操作的同时进行。但是,在同一时刻,它只允许有一个写操作在进行。并且,在某一个写操作被进行的过程中,读操作的进行也是不被允许的。也就是说,读写锁控制下的多个写操作之间都是互斥的,并且写操作与读操作之间也都是互斥的。但是,多个读操作之间却不存在互斥关系。
换句话说:
- 同时只能有一个 goroutine 能够获得写锁定。
- 同时可以有任意多个 gorouinte 获得读锁定。
- 同时只能存在写锁定或读锁定(读和写互斥)。
WaitGroup
sync.WaitGroup 可以等待一组 Goroutine 的返回,一个比较常见的使用场景是批量发出 RPC 或者 HTTP 请求:
1 | requests := []*Request{...} |
我们可以通过 sync.WaitGroup 将原本顺序执行的代码在多个 Goroutine 中并发执行,加快程序处理的速度。
WaitGroup 用于等待一组 goroutine 结束,用法很简单。它有三个方法:
1 | func (wg *WaitGroup) Add(delta int) |
- Add 用来添加 goroutine 的个数
- Done 执行一次数量减 1
- Wait 用来等待结束
通过对 sync.WaitGroup 的分析和研究,我们能够得出以下结论:
sync.WaitGroup必须在sync.WaitGroup.Wait方法返回之后才能被重新使用;sync.WaitGroup.Done只是对sync.WaitGroup.Add方法的简单封装,我们可以向sync.WaitGroup.Add方法传入任意负数(需要保证计数器非负)快速将计数器归零以唤醒等待的 Goroutine;- 可以同时有多个 Goroutine 等待当前
sync.WaitGroup计数器的归零,这些 Goroutine 会被同时唤醒;
Once
Go 语言标准库中 sync.Once 可以保证在 Go 程序运行期间的某段代码只会执行一次。在运行如下所示的代码时,我们会看到如下所示的运行结果:
1 | func main() { |
作为用于保证函数执行次数的 sync.Once 结构体,它使用互斥锁和 sync/atomic 包提供的方法实现了某个函数在程序运行期间只能执行一次的语义。在使用该结构体时,我们也需要注意以下的问题:
sync.Once.Do方法中传入的函数只会被执行一次,哪怕函数中发生了panic;- 两次调用
sync.Once.Do方法传入不同的函数只会执行第一次调传入的函数;
Cond
Go 语言标准库中还包含条件变量 sync.Cond,它可以让一组的 Goroutine 都在满足特定条件时被唤醒。每一个 sync.Cond 结构体在初始化时都需要传入一个互斥锁,我们可以通过下面的例子了解它的使用方法:
声明
1 | lock := new(sync.Mutex) |
也可以写成一行
1 | cond := sync.NewCond(new(sync.Mutex)) |
方法
1 | cond.L.Lock() |
Note
cond.L.Lock()和cond.L.Unlock():也可以使用lock.Lock()和lock.Unlock(),完全一样,因为是指针转递cond.Wait():Unlock()->*阻塞等待通知(即等待Signal()或Broadcast()的通知)->收到通知*->Lock()cond.Signal():通知一个Wait()了的,若没有Wait(),也不会报错。Signal()通知的顺序是根据原来加入通知列表(Wait())的先入先出cond.Broadcast(): 通知所有Wait()了的,若没有Wait(),也不会报错
1 | var status int64 |
上述代码同时运行了 11 个 Goroutine,这 11 个 Goroutine 分别做了不同事情:
- 10 个 Goroutine 通过
sync.Cond.Wait等待特定条件的满足; - 1 个 Goroutine 会调用
sync.Cond.Broadcast唤醒所有陷入等待的 Goroutine;
调用 sync.Cond.Broadcast 方法后,上述代码会打印出 10 次 “listen” 并结束调用。
SingleFlight
golang/sync/singleflight.Group 是 Go 语言扩展包中提供了另一种同步原语,它能够在一个服务中抑制对下游的多次重复请求。一个比较常见的使用场景是:我们在使用 Redis 对数据库中的数据进行缓存,发生缓存击穿时,大量的流量都会打到数据库上进而影响服务的尾延时。
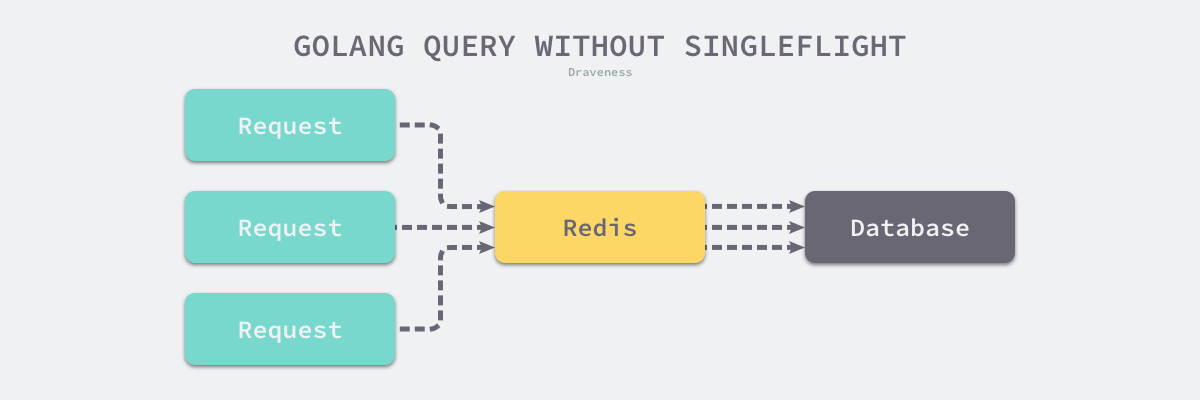
图 6-12 Redis 缓存击穿问题
但是 golang/sync/singleflight.Group 能有效地解决这个问题,它能够限制对同一个键值对的多次重复请求,减少对下游的瞬时流量。
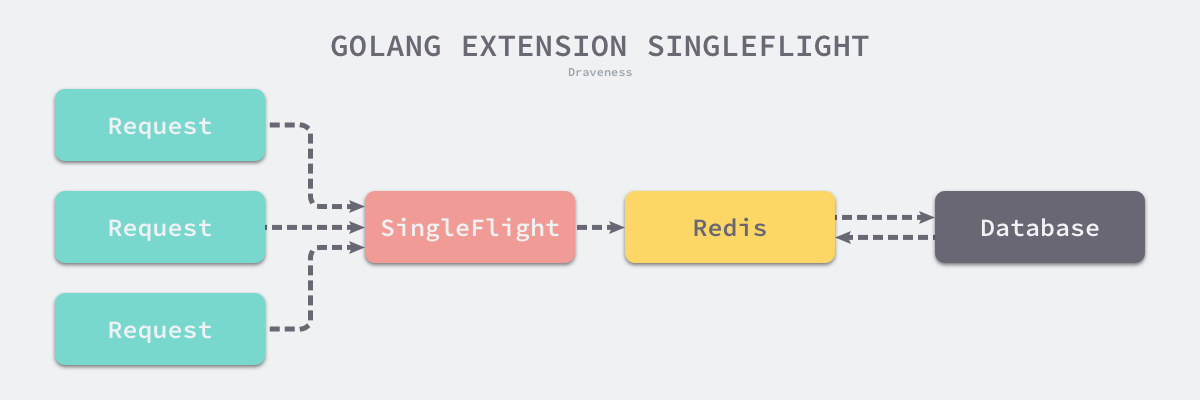
图 6-13 缓解缓存击穿问题
在资源的获取非常昂贵时(例如:访问缓存、数据库),就很适合使用 golang/sync/singleflight.Group 优化服务。我们来了解一下它的使用方法:
1 | type service struct { |
因为请求的哈希在业务上一般表示相同的请求,所以上述代码使用它作为请求的键。当然,我们也可以选择其他的字段作为 golang/sync/singleflight.Group.Do 方法的第一个参数减少重复的请
Channel
Go 语言中最常见的、也是经常被人提及的设计模式就是:不要通过共享内存的方式进行通信,而是应该通过通信
的方式共享内存。在很多主流的编程语言中,多个线程传递数据的方式一般都是共享内存,为了解决线程竞争,我
们需要限制同一时间能够读写这些变量的线程数量,然而这与 Go 语言鼓励的设计并不相同。
虽然我们在 Go 语言中也能使用共享内存加互斥锁进行通信,但是 Go 语言提供了一种不同的并发模型,即通信顺
序进程(Communicating sequential processes,CSP)1。Goroutine 和 Channel 分别对应 CSP 中的实体和传
递信息的媒介,Goroutine 之间会通过 Channel 传递数据
向channel发送数据
我们在这里可以简单梳理和总结一下使用 ch <- i 表达式向 Channel 发送数据时遇到的几种情况:
- 如果当前 Channel 的
recvq上存在已经被阻塞的 Goroutine,那么会直接将数据发送给当前 Goroutine 并将其设置成下一个运行的 Goroutine; - 如果 Channel 存在缓冲区并且其中还有空闲的容量,我们会直接将数据存储到缓冲区
sendx所在的位置上; - 如果不满足上面的两种情况,会创建一个
runtime.sudog结构并将其加入 Channel 的sendq队列中,当前 Goroutine 也会陷入阻塞等待其他的协程从 Channel 接收数据;
发送数据的过程中包含几个会触发 Goroutine 调度的时机:
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的
runnext属性,但是并不会立刻触发调度; - 发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 Channel 的
sendq队列并调用runtime.goparkunlock触发 Goroutine 的调度让出处理器的使用权;
接收channel数据
我们梳理一下从 Channel 中接收数据时可能会发生的五种情况:
- 如果 Channel 为空,那么会直接调用
runtime.gopark挂起当前 Goroutine; - 如果 Channel 已经关闭并且缓冲区没有任何数据,
runtime.chanrecv会直接返回; - 如果 Channel 的
sendq队列中存在挂起的 Goroutine,会将recvx索引所在的数据拷贝到接收变量所在的内存空间上并将sendq队列中 Goroutine 的数据拷贝到缓冲区; - 如果 Channel 的缓冲区中包含数据,那么直接读取
recvx索引对应的数据; - 在默认情况下会挂起当前的 Goroutine,将
runtime.sudog结构加入recvq队列并陷入休眠等待调度器的唤醒;
我们总结一下从 Channel 接收数据时,会触发 Goroutine 调度的两个时机:
- 当 Channel 为空时;
- 当缓冲区中不存在数据并且也不存在数据的发送者时;
关闭channel
close方法
Goroutine
历程
单线程调度器 ·0.x
- 只包含 40 多行代码;
- 程序中只能存在一个活跃线程,由 G-M 模型组成;
多线程调度器 ·1.0
- 允许运行多线程的程序;
- 全局锁导致竞争严重;
任务窃取调度器 ·1.1
- 引入了处理器 P,构成了目前的 G-M-P 模型;
- 在处理器 P 的基础上实现了基于工作窃取的调度器;
- 在某些情况下,Goroutine 不会让出线程,进而造成饥饿问题;
- 时间过长的垃圾回收(Stop-the-world,STW)会导致程序长时间无法工作;
抢占式调度器 ·1.2
~ 至今
- 基于协作的抢占式调度器 - 1.2 ~ 1.13
- 通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前 Goroutine 是否发起了抢占请求,实现基于协作的抢占式调度;
- Goroutine 可能会因为垃圾回收和循环长时间占用资源导致程序暂停;
- 基于信号的抢占式调度器 - 1.14 ~ 至今
- 实现基于信号的真抢占式调度;
- 垃圾回收在扫描栈时会触发抢占调度;
- 抢占的时间点不够多,还不能覆盖全部的边缘情况;
- 基于协作的抢占式调度器 - 1.2 ~ 1.13
非均匀存储访问调度器 · 提案
- 对运行时的各种资源进行分区;
- 实现非常复杂,到今天还没有提上日程;
Go 语言在并发编程方面有强大的能力,这离不开语言层面对并发编程的支持
谈到 Go 语言调度器,我们绕不开的是操作系统、进程与线程这些概念,线程是操作系统调度时的最基本单元,而 Linux 在调度器并不区分进程和线程的调度,它们在不同操作系统上也有不同的实现,但是在大多数的实现中线程都属于进程:
在默认情况下,一个四核机器会创建四个活跃的操作系统线程,每一个线程都对应一个运行时中的 runtime.m 结构体。
在大多数情况下,我们都会使用 Go 的默认设置,也就是线程数等于 CPU 数,默认的设置不会频繁触发操作系统的线程调度和上下文切换,所有的调度都会发生在用户态,由 Go 语言调度器触发,能够减少很多额外开销。
1 | func schedinit() { |
在调度器初始函数执行的过程中会将 maxmcount 设置成 10000,这也就是一个 Go 语言程序能够创建的最大线程数,虽然最多可以创建 10000 个线程,但是可以同时运行的线程还是由 GOMAXPROCS 变量控制。
后续需要重新研究
调度器的设计策略
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
1)work stealing 机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
2)hand off 机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
转自链接:https://learnku.com/articles/41728
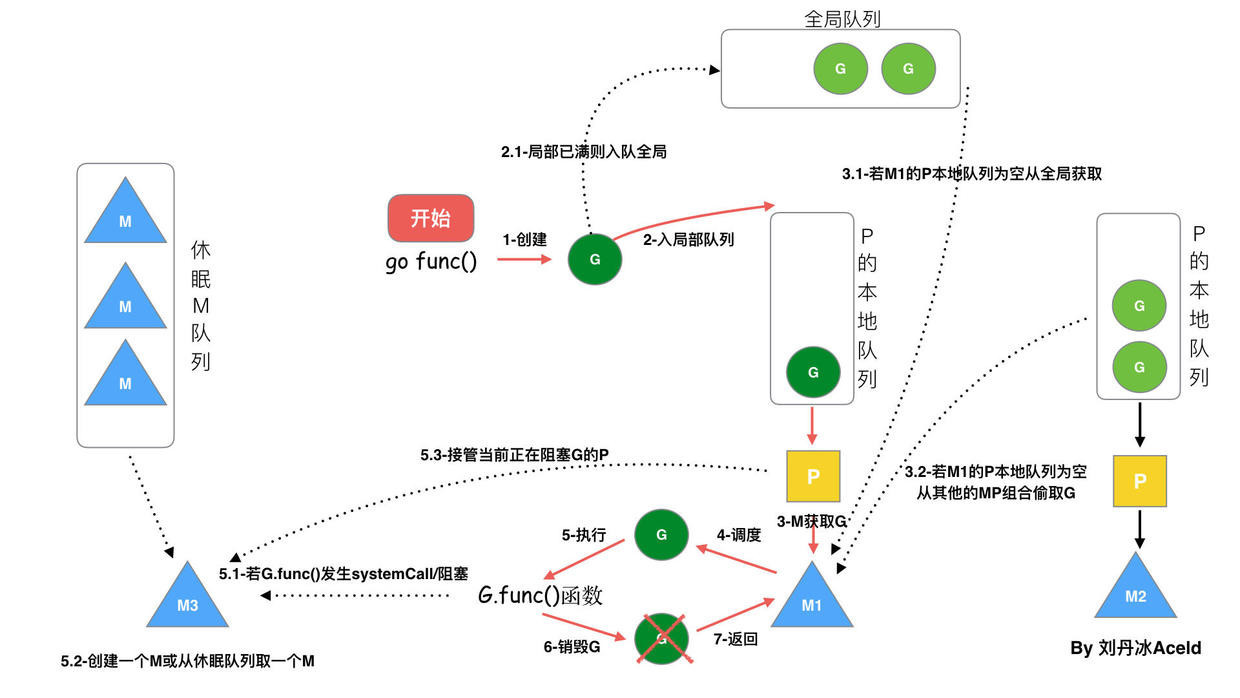
G1 本地队列 G5、G6 已经被其他 M 偷走并运行完成,当前 M1 和 M2 分别在运行 G2 和 G8,M3 和 M4 没有 goroutine 可以运行,M3 和 M4 处于自旋状态,它们不断寻找 goroutine。
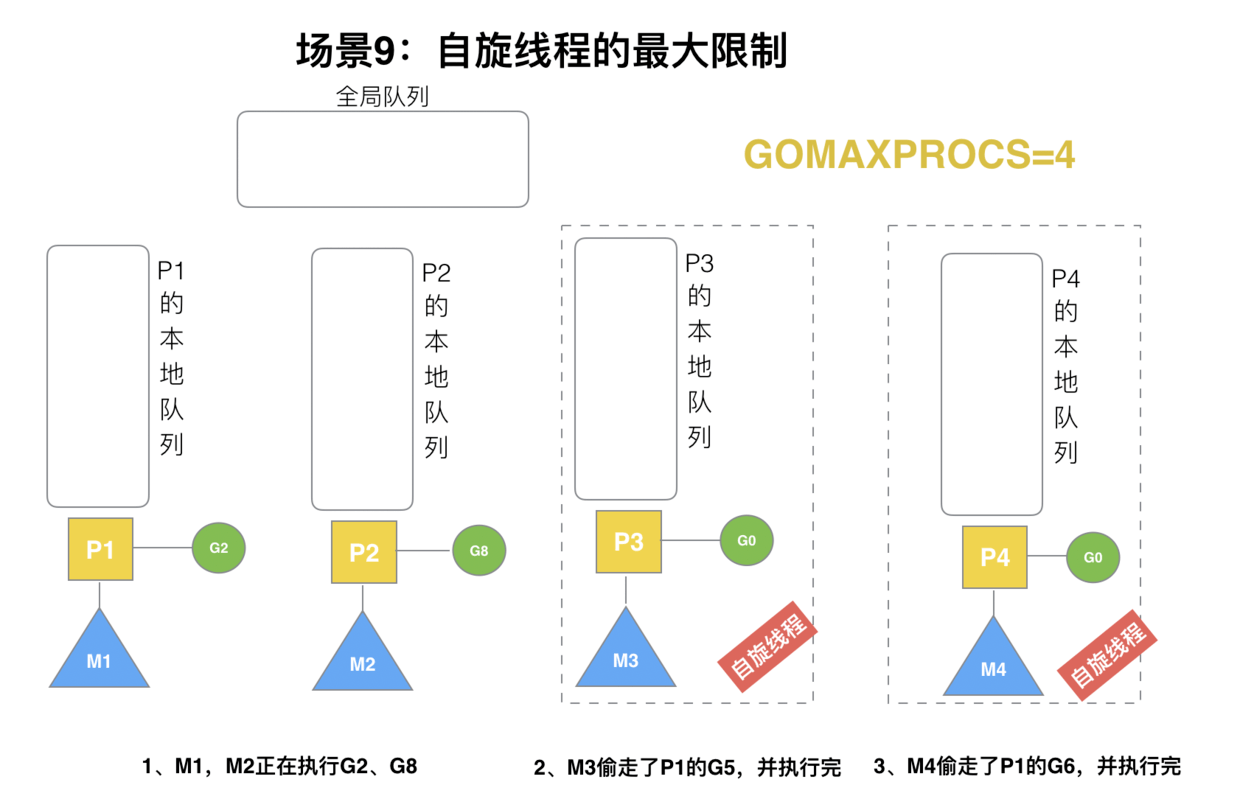
为什么要让 m3 和 m4 自旋,自旋本质是在运行,线程在运行却没有执行 G,就变成了浪费 CPU. 为什么不销毁现场,来节约 CPU 资源。因为创建和销毁 CPU 也会浪费时间,我们希望当有新 goroutine 创建时,立刻能有 M 运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费 CPU,所以系统中最多有 GOMAXPROCS 个自旋的线程 (当前例子中的 GOMAXPROCS=4,所以一共 4 个 P),多余的没事做线程会让他们休眠。
P:processor,处理器,调度G到M上,其维护了一个队列,存储了所有需要它来调度的G。
在程序启动时会根据GOMAXPROCS配置的个数创建对应个数的P。
注意:GOMAXPROCS 在容器中 会获取宿主机的核数 需要提前设置好 线程过多,会增加上线文切换的负担,白白浪费CPU。
可视化 GMP 编程
go tool trace
网络轮询器
IO密集型与CPU密集型
在今天,大部分的服务都是 I/O 密集型的,应用程序会花费大量时间等待 I/O 操作的完成。网络轮询器是 Go 语言运行时用来处理 I/O 操作的关键组件,它使用了操作系统提供的 I/O 多路复用机制增强程序的并发处理能力。本节会深入分析 Go 语言网络轮询器的设计与实现原理。
IO密集型和CPU密集型
- 一个计算为主的应用程序(CPU密集型程序),多线程或多进程跑的时候,可以充分利用起所有的 CPU 核心数,比如说16核的CPU ,开16个线程的时候,可以同时跑16个线程的运算任务,此时是最大效率。但是如果线程数/进程数远远超出 CPU 核心数量,反而会使得任务效率下降,因为频繁的切换线程或进程也是要消耗时间的。因此对于 CPU 密集型的任务来说,线程数/进程数等于 CPU 数是最好的了。
- 如果是一个磁盘或网络为主的应用程序(IO密集型程序),一个线程处在 IO 等待的时候,另一个线程还可以在 CPU 里面跑,有时候 CPU 闲着没事干,所有的线程都在等着 IO,这时候他们就是同时的了,而单线程的话,此时还是在一个一个等待的。我们都知道IO的速度比起 CPU 来是很慢的。此时线程数可以是CPU核心数的数倍(视情况而定)。
CPU密集型举例:
一个方法内部的逻辑,主要是需要序列化反序列化、加密解密、向量计算、大量循环判断和加减乘除运算,这些都是典型的CPU密集型场景。(Jvm垃圾回收器也是)
也可以说,大量用到了计算机的CPU硬件资源的业务逻辑,就是CPU密集型场景。还可以说,除了IO以外的,都是CPU密集型。
IO密集型举例:
数据库(可扩展) 缓存的读取RPC http 读取本地文件
线程和CPU核心的关系?
一个cpu核心 运行多个线程 会造成线程的切换
需要多少线程?值得注意的是,线程不是越多越好。如果你的线程是不涉及任何I/O、没有任何同步互斥之类的纯计算类型,那么每个核心一个线程通常是最佳选择。但通常来说,线程都需要一定的I/O,可能需要一定的同步互斥,那么这时适当增加线程可能会提高性能,但当线程数量到达一个临界值后性能开始下降,这时线程间切换的开销将显著增加。这里之所以用适当这个词,是因为这很难去量化,只能用你实际的程序根据真正的场景进行测试才能得到这个值。
从上述IO和CPU三个角度的描述来看,我们也可以看出为什么CPU密集型的线程数要相对小很多(线程核数的量级),为什么IO密集型可以远大于核数。就是因为:
CPU密集型已经在不断地计算了,再开更多的线程也是得等CPU空闲出来,没意义,不会算得更快了;
而IO密集型是大量的再等待,CPU是空闲的,开启更多的线程可以让并发的请求更多,从而降低对外接口(方法)耗时,提升吞吐量。
磁盘IO-为什么说IO密集型很少消耗CPU资源?_lz710117239的博客-CSDN博客_io操作占用cpu资源吗
用户空间 到 内核空间的拷贝是 cpu来执行
内核空间 到 硬盘 网络 是DMA执行
DMA 速度 相对于CPU存取速度极慢
导致 对于IO密集型程序 只有开始阶段会用到cpu拷贝 后面大部分时间CPU都在等待DMA执行,
此时优化可以用多线程 让多线程赶快处理下一个程序 而不用等待IO阻塞
若是CPU密集型的程序 单核多线程由于切换损耗 时间反而大于 顺序执行
1 | CPU计算文件地址 ==> 委派DMA读取文件 ==> DMA接管总线 ==> CPU的A进程阻塞,挂起 ==> CPU切换到B进程 ==> DMA读完文件后通知CPU(一个中断异常) ==> CPU切换回A进程操作文件 |
提问 数据库读写 是IO密集型吗 过程是怎么样的??
I/O操作为什么不需要cpu_hllyzms的博客-CSDN博客_io操作需要cpu吗
CPU 核数与线程数有什么关系? - ludongguoa - 博客园 (cnblogs.com)
1.单独的地址空间
根据大多书上的理论知识,目前我们应该很清楚,进程就是比线程多了一些东西,而最重要的应该是多了自己的虚拟地址空间。
线程拥有的资源很有限,只有个栈,然后在上面建立中断栈帧,运行必要的上下文等,也就是通常书上所说的寄存器资源。而进程拥有整个虚拟地址空间,整整 4 GB,它能在上面建立的东西可就太多了,堆栈,数据代码段等等,甚至还包括了线程所拥有的资源,这也就是为什么说线程要依赖于进程存在的原因。
所以可以说进程和线程最主要的区别就是有没有自己的地址空间,进程的其他特有的机制都是建立在地址空间之上的,而有没有地址空间就是有没有自己的页表,那么进程的task_struct可以如下定义:

前面说过,进程依据线程实现,所以进程线程用的是同一个任务结构体,只是进程的pgdir有实际的值,而线程的pgdir设为NULL。
2.特权级3用户态下工作
进程的另一特点就是运行在 3 特权级,进程的创建在内核态下实现,如果调度的是进程,需要从内核态返回用户态,高特权级转成低特权级。而CPU一般不会允许从高特权级转回低特权级,只有一种情况例外,中断返回。
线程运行是模仿函数调用然后返回执行的,而这里我们进入 3 特权级则是模仿中断然后返回到 3 特权级,实有异曲同工之妙。关于中断栈帧的结构体线程那一块已经定义,这里不再赘述,直接看进程的创建。
内存管理
内存管理一般包含三个不同的组件,分别是用户程序(Mutator)、分配器(Allocator)和收集器(Collector)1,当用户程序申请内存时,它会通过内存分配器申请新内存,而分配器会负责从堆中初始化相应的内存区域。
设计原理
内存分配器
1.线性分配器
线性分配器只需再内存中维护一个指向内存特定位置得指针,用户程序向分配器申请内存,分配器只需要检查剩余内存,返回分配内存并修改指针位置
有较快得执行速度 和 较低得实现复杂度,但是线性分配器无法在内存被释放时重用内存。
2.空闲链表分配器
可以重用已经被释放的内存,它在内部会维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表:
分配内存需要遍历链表 所以时间复杂度是On
Go语言得内存分配策略和 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块 有些相同
它会将内存分割成由 4、8、16、32 字节的内存块组成的链表,当我们向内存分配器申请 8 字节的内存时,它会在找到满足条件的空闲内存块并返回
这样可以减少遍历次数 提高了内存分配的效率
分级分配机制
Go语言的内存分配器,运行时根据对象的大小将对象分成微对象、小对象和大对象三种:
| 类别 | 大小 |
|---|---|
| 微对象 | (0, 16B) |
| 小对象 | [16B, 32KB] |
| 大对象 | (32KB, +∞) |
因为程序中的绝大多数对象的大小都在 32KB 以下,而申请的内存大小影响 Go 语言运行时分配内存的过程和开
销,所以分别处理大对象和小对象有利于提高内存分配器的性能
多级缓存
内存分配器不仅会区别对待大小不同的对象,还会将内存分成不同的级别分别管理,TCMalloc 和 Go 运行时分配器都会引入线程缓存(Thread Cache)、中心缓存(Central Cache)和页堆(Page Heap)三个组件分级管理内存。
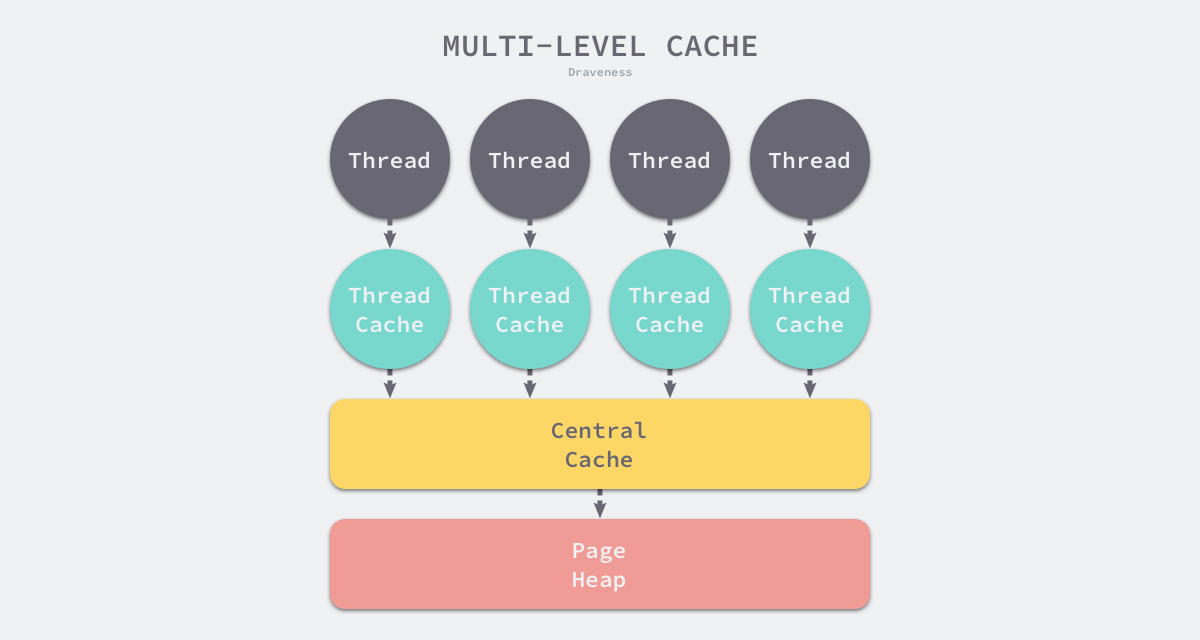
线程缓存属于每一个独立的线程,它能够满足线程上绝大多数的内存分配需求,因为不涉及多线程,所以也不需要
使用互斥锁来保护内存,这能够减少锁竞争带来的性能损耗。当线程缓存不能满足需求时,运行时会使用中心缓存
作为补充解决小对象的内存分配,在遇到 32KB 以上的对象时,内存分配器会选择页堆直接分配大内存。
这种多层级的内存分配设计与计算机操作系统中的多级缓存有些类似,因为多数的对象都是小对象,我们可以通过
线程缓存和中心缓存提供足够的内存空间,发现资源不足时从上一级组件中获取更多的内存资源。
虚拟内存布局
在 Go 语言 1.10 以前的版本,堆区的内存空间都是连续的;但是在 1.11 版本,Go 团队使用稀疏的堆内存空间替代了连续的内存,解决了连续内存带来的限制以及在特殊场景下可能出现的问题。
1.线性内存
Go 语言程序的 1.10 版本在启动时会初始化整片虚拟内存区域,如下所示的三个区域 spans、bitmap 和 arena 分别预留了 512MB、16GB 以及 512GB 的内存空间,这些内存并不是真正存在的物理内存,而是虚拟内存:
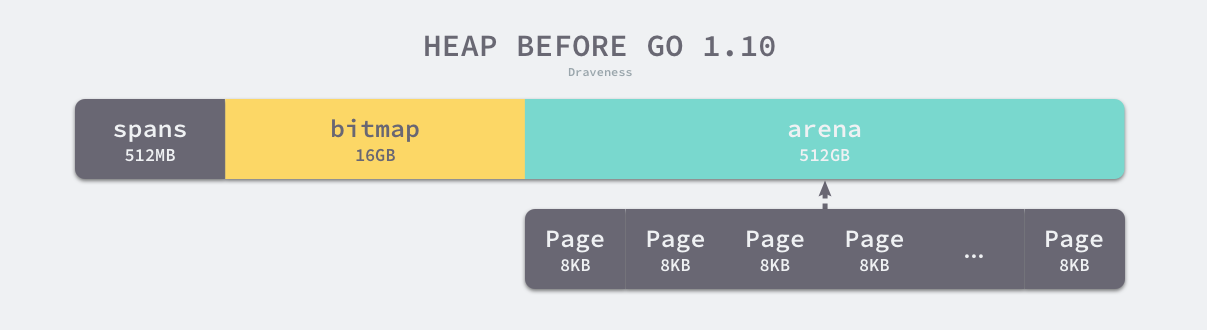
spans区域存储了指向内存管理单元runtime.mspan的指针,每个内存单元会管理几页的内存空间,每页大小为 8KB;bitmap用于标识arena区域中的那些地址保存了对象,位图中的每个字节都会表示堆区中的 32 字节是否空闲;arena区域是真正的堆区,运行时会将 8KB 看做一页,这些内存页中存储了所有在堆上初始化的对象;
对于任意一个地址,我们都可以根据 arena 的基地址计算该地址所在的页数并通过 spans 数组获得管理该片内存的管理单元 runtime.mspan,spans 数组中多个连续的位置可能对应同一个 runtime.mspan 结构。
不足之处:
2.稀疏内存
稀疏内存是 Go 语言在 1.11 中提出的方案,使用稀疏的内存布局不仅能移除堆大小的上限5,还能解决 C 和 Go 混合使用时的地址空间冲突问题6。不过因为基于稀疏内存的内存管理失去了内存的连续性这一假设,这也使内存管理变得更加复杂:
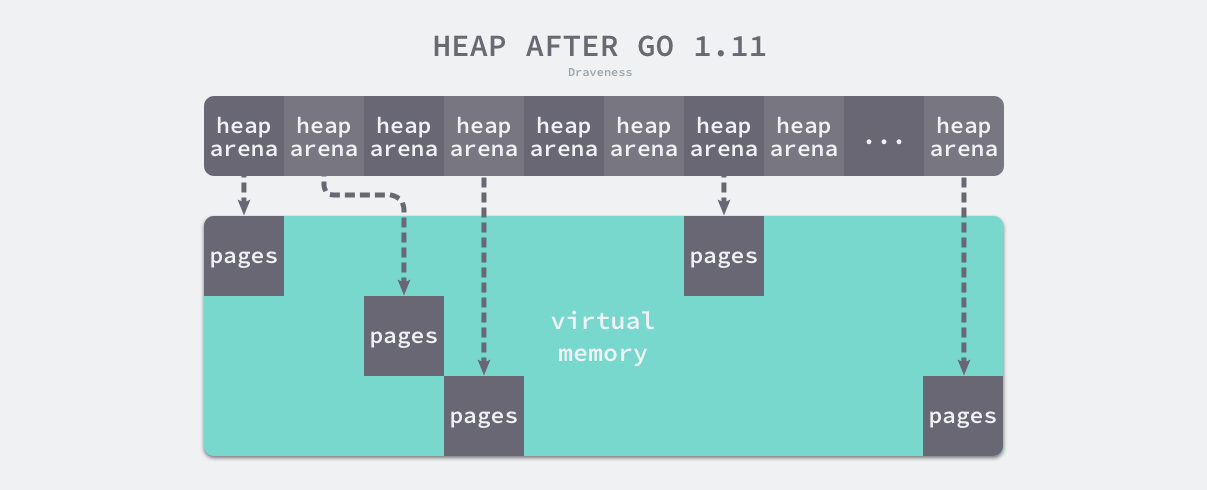
运行时使用二维的 runtime.heapArena 数组管理所有的内存,每个单元都会管理 64MB 的内存空间:
1 | type heapArena struct { |
该结构体中的 bitmap 和 spans 与线性内存中的 bitmap 和 spans 区域一一对应,zeroedBase 字段指向了该结构体管理的内存的基地址。上述设计将原有的连续大内存切分成稀疏的小内存,而用于管理这些内存的元信息也被切成了小块。
地址空间
因为所有的内存最终都是要从操作系统中申请的,所以 Go 语言的运行时构建了操作系统的内存管理抽象层,该抽象层将运行时管理的地址空间分成以下四种状态8:
| 状态 | 解释 |
|---|---|
None |
内存没有被保留或者映射,是地址空间的默认状态 |
Reserved |
运行时持有该地址空间,但是访问该内存会导致错误 |
Prepared |
内存被保留,一般没有对应的物理内存访问该片内存的行为是未定义的可以快速转换到 Ready 状态 |
Ready |
可以被安全访问 |
内存管理组件
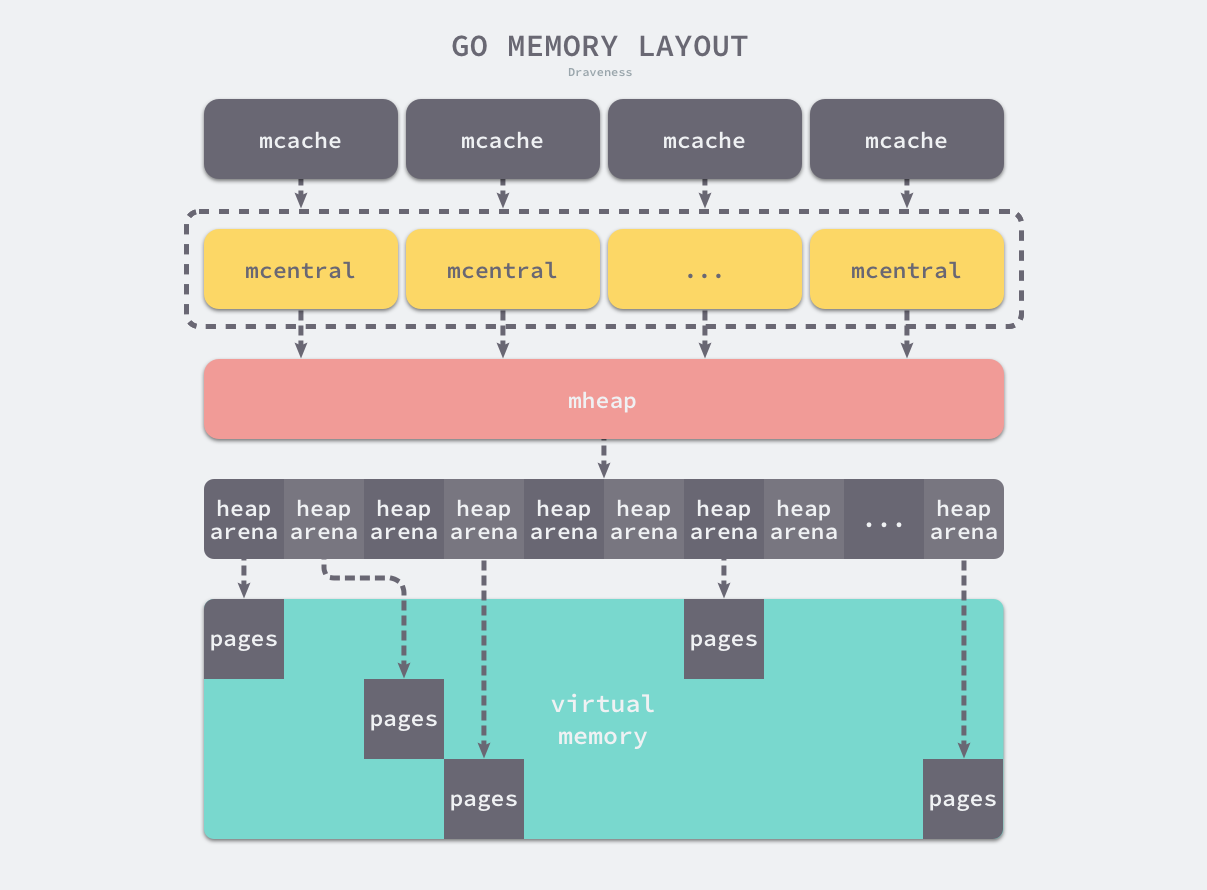
内存管理单元
runtime.mspan 是 Go 语言内存管理的基本单元,该结构体中包含 next 和 prev 两个字段,它们分别指向了前一个和后一个 runtime.mspan:
每个 runtime.mspan 都管理 npages 个大小为 8KB 的页,这里的页不是操作系统中的内存页,它们是操作系统内存页的整数倍,该结构体会使用下面这些字段来管理内存页的分配和回收:
runtime.mspan 会以两种不同的视角看待管理的内存,当结构体管理的内存不足时,运行时会以页为单位向堆申请内存:
当用户程序或者线程向 runtime.mspan 申请内存时,它会使用 allocCache 字段以对象为单位在管理的内存中快速查找待分配的空间:
线程缓存
runtime.mcache 是 Go 语言中的线程缓存,它会与线程上的处理器一一绑定,主要用来缓存用户程序申请的微小对象。每一个线程缓存都持有 68 * 2 个 runtime.mspan,这些内存管理单元都存储在结构体的 alloc 字段中:
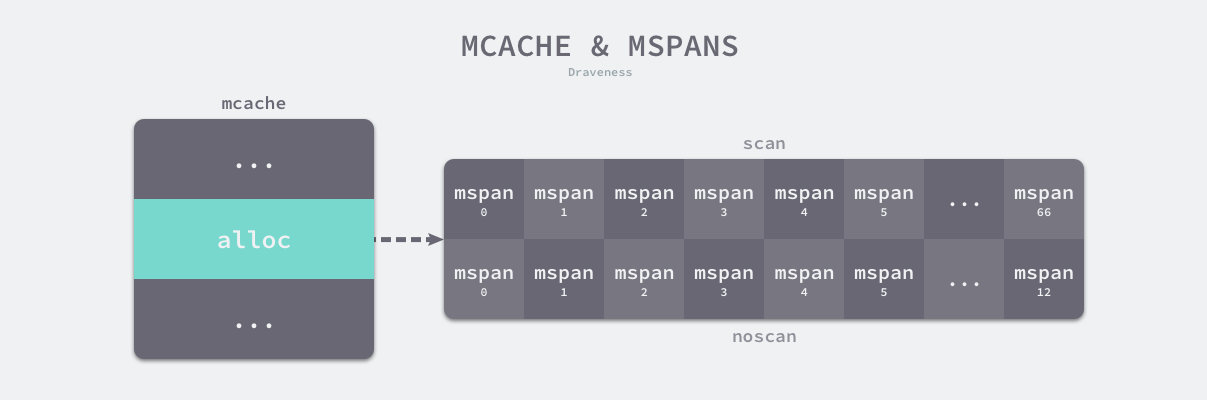
线程缓存在刚刚被初始化时是不包含 runtime.mspan 的,只有当用户程序申请内存时才会从上一级组件获取新的 runtime.mspan 满足内存分配的需求。
中心缓存
runtime.mcentral 是内存分配器的中心缓存,与线程缓存不同,访问中心缓存中的内存管理单元需要使用互斥锁:
每个中心缓存都会管理某个跨度类的内存管理单元,它会同时持有两个 runtime.spanSet,分别存储包含空闲对象和不包含空闲对象的内存管理单元。
页堆
runtime.mheap 是内存分配的核心结构体,Go 语言程序会将其作为全局变量存储,而堆上初始化的所有对象都由该结构体统一管理,该结构体中包含两组非常重要的字段,其中一个是全局的中心缓存列表 central,另一个是管理堆区内存区域的 arenas 以及相关字段。
每一个 runtime.heapArena 都会管理 64MB 的内存空间。
流程:xxxx
内存分配
- 微对象
(0, 16B)— 先使用微型分配器,再依次尝试线程缓存、中心缓存和堆分配内存; - 小对象
[16B, 32KB]— 依次尝试使用线程缓存、中心缓存和堆分配内存; - 大对象
(32KB, +∞)— 直接在堆上分配内存;
小结:
内存分配是 Go 语言运行时内存管理的核心逻辑,运行时的内存分配器使用类似 TCMalloc 的分配策略将对象根据大小分类,并设计多层级的组件提高内存分配器的性能
微对象
Go 语言运行时将小于 16 字节的对象划分为微对象,它会使用线程缓存上的微分配器提高微对象分配的性能,我
们主要使用它来分配较小的字符串以及逃逸的临时变量。微分配器可以将多个较小的内存分配请求合入同一个内存
块中,只有当内存块中的所有对象都需要被回收时,整片内存才可能被回收。
若微分配器已经在 16 字节的内存块中分配了 12 字节的对象,如果下一个待分配的对象小于 4 字节,它会直接使
用上述内存块的剩余部分,减少内存碎片,不过该内存块只有所有对象都被标记为垃圾时才会回收。
当内存块中不包含空闲的内存时,下面的这段代码会先从线程缓存找到跨度类对应的内存管理单元
runtime.mspan,调用 runtime.nextFreeFast 获取空闲的内存;当不存在空闲内存时,我们会调用
runtime.mcache.nextFree 从中心缓存或者页堆中获取可分配的内存块
垃圾回收
相信很多人对垃圾收集器的印象都是暂停程序(Stop the world,STW),随着用户程序申请越来越多的内存,系统中的垃圾也逐渐增多;当程序的内存占用达到一定阈值时,整个应用程序就会全部暂停,垃圾收集器会扫描已经分配的所有对象并回收不再使用的内存空间,当这个过程结束后,用户程序才可以继续执行,Go 语言在早期也使用这种策略实现垃圾收集,但是今天的实现已经复杂了很多。
1.标记清除
标记清除(Mark-Sweep)算法是最常见的垃圾收集算法,标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表;
2.三色抽象
为了解决原始标记清除算法带来的长时间 STW,多数现代的追踪式垃圾收集器都会实现三色标记算法的变种以缩短 STW 的时间。三色标记算法将程序中的对象分成白色、黑色和灰色三类4:
- 白色对象 — 潜在的垃圾,其内存可能会被垃圾收集器回收;
- 黑色对象 — 活跃的对象,包括不存在任何引用外部指针的对象以及从根对象可达的对象;
- 灰色对象 — 活跃的对象,因为存在指向白色对象的外部指针,垃圾收集器会扫描这些对象的子对象;
在垃圾收集器开始工作时,程序中不存在任何的黑色对象,垃圾收集的根对象会被标记成灰色,垃圾收集器只会从灰色对象集合中取出对象开始扫描,当灰色集合中不存在任何对象时,标记阶段就会结束。
三色标记垃圾收集器的工作原理很简单,我们可以将其归纳成以下几个步骤:
- 从灰色对象的集合中选择一个灰色对象并将其标记成黑色;
- 将黑色对象指向的所有对象都标记成灰色,保证该对象和被该对象引用的对象都不会被回收;
- 重复上述两个步骤直到对象图中不存在灰色对象;
三色错误的回收,需要用到屏障技术。
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,目前多数的现代处理器都会乱序执行指令以最大化性能,但是该技术能够保证内存操作的顺序性,在内存屏障前执行的操作一定会先于内存屏障后执行的操作6
Go 语言中使用的两种写屏障技术,分别是 Dijkstra 提出的插入写屏障8和 Yuasa 提出的删除写屏障9,这里会分析它们如何保证三色不变性和垃圾收集器的正确性。
申请内存:
- 当前线程的内存管理单元中不存在空闲空间时,创建微对象和小对象需要调用
runtime.mcache.nextFree从中心缓存或者页堆中获取新的管理单元,在这时就可能触发垃圾收集; - 当用户程序申请分配 32KB 以上的大对象时,一定会构建
runtime.gcTrigger结构体尝试触发垃圾收集;
栈内存管理
分段栈
分段栈是 Go 语言在 v1.3 版本之前的实现,所有 Goroutine 在初始化时都会调用 runtime.stackalloc:go1.2 分配一块固定大小的内存空间,这块内存的大小由 runtime.StackMin:go1.2 表示,在 v1.2 版本中为 8KB:
如果通过该方法申请的内存大小为固定的 8KB 或者满足其他的条件,运行时会在全局的栈缓存链表中找到空闲的内存块并作为新 Goroutine 的栈空间返回;在其余情况下,栈内存空间会从堆上申请一块合适的内存。
分段栈机制虽然能够按需为当前 Goroutine 分配内存并且及时减少内存的占用,但是它也存在两个比较大的问题:
- 如果当前 Goroutine 的栈几乎充满,那么任意的函数调用都会触发栈扩容,当函数返回后又会触发栈的收缩,如果在一个循环中调用函数,栈的分配和释放就会造成巨大的额外开销,这被称为热分裂问题(Hot split);
- 一旦 Goroutine 使用的内存越过了分段栈的扩缩容阈值,运行时会触发栈的扩容和缩容,带来额外的工作量;
连续栈
连续栈可以解决分段栈中存在的两个问题,其核心原理是每当程序的栈空间不足时,初始化一片更大的栈空间并将原栈中的所有值都迁移到新栈中,新的局部变量或者函数调用就有充足的内存空间。使用连续栈机制时,栈空间不足导致的扩容会经历以下几个步骤:
- 在内存空间中分配更大的栈内存空间;
- 将旧栈中的所有内容复制到新栈中;
- 将指向旧栈对应变量的指针重新指向新栈;
- 销毁并回收旧栈的内存空间;
因为需要拷贝变量和调整指针,连续栈增加了栈扩容时的额外开销,但是通过合理栈缩容机制就能避免热分裂带来的性能问题10,在 GC 期间如果 Goroutine 使用了栈内存的四分之一,那就将其内存减少一半,这样在栈内存几乎充满时也只会扩容一次,不会因为函数调用频繁扩缩容
缺点
插件系统
静态库和动态库的优缺点也比较明显;只依赖静态库并且通过静态链接生成的二进制文件因为包含了全部的依赖,所以能够独立执行,但是编译的结果也比较大;(Go 默认的方式 直接生产可执行文件)
而动态库可以在多个可执行文件之间共享,可以减少内存的占用,其链接的过程往往也都是在装载或者运行期间触发的,所以可以包含一些可以热插拔的模块并降低内存的占用。
使用静态链接编译二进制文件在部署上有非常明显的优势,最终的编译产物也可以直接运行在大多数的机器上,静
态链接带来的部署优势远比更低的内存占用显得重要,所以很多编程语言包括 Go 都将静态链接作为默认的链接方
式。
HTTP协议
在应用层协议中,最常见的两种解决方案是基于长度或者基于终结符(Delimiter)。HTTP 协议其实同时实现了上述两种方案,在多数情况下 HTTP 协议都会在协议头中加入 Content-Length 表示负载的长度,消息的接收者解析到该协议头之后就可以确定当前 HTTP 请求/响应结束的位置,分离不同的 HTTP 消息,下面就是一个使用 Content-Length 划分消息边界的例子:
不过 HTTP 协议除了使用基于长度的方式实现边界,也会使用基于终结符的策略,当 HTTP 使用块传输(Chunked Transfer)机制时,HTTP 头中就不再包含 Content-Length 了,它会使用负载大小为 0 的 HTTP 消息作为终结符表示消息的边界。
需要关注的知识点
Golang 位运算实战用法 - 掘金 (juejin.cn)
1 | # 火焰图 需要 ctrl+c 停止程序 |
Go性能分析工具pprof - 知乎 (zhihu.com)
让你最快上手 go 的 pprof 性能分析大杀器 - 腾讯云开发者社区-腾讯云 (tencent.com)
go - 实战Go内存泄露_个人文章 - SegmentFault 思否
谁占了该CPU核的30% - 一个较意外的Go性能问题 - 知乎 (zhihu.com)
Golang 反射性能优化 - 知乎 (zhihu.com)
golang笔记——深入了解netpoller - 简书 (jianshu.com)
一文搞懂select、poll和epoll区别 - 知乎 (zhihu.com)
rune类型
rune 是类型 int32 的别名,在所有方面都等价于它
1.统计带其余字体得字符串
1 | // 转换成 rune 数组后统计字符串长度 |
2.截取带中文字符串
1 | s := "Go语言编程" |
Go 语言把字符分 byte 和 rune 两种类型处理。byte 是类型 unit8 的别名,用于存放占 1 字节的 ASCII 字符,如英文字符,返回的是字符原始字节。rune 是类型 int32 的别名,用于存放多字节字符,如占 3 字节的中文字符,返回的是字符 Unicode 码点值。如下图所示:
1 | s := "Go语言编程" |
go 空接口的理解
Go1.16逃逸分析原理剖析 - 掘金 (juejin.cn)
一文搞懂golang内存逃逸分析 - 掘金 (juejin.cn)
一面问我map实现原理
问我goroutinue调度
还问不同方法初始化切片的区别
for range 陷阱
a. 是否支持while循环,如何实现这种机制
b. 哪些数据类型只能用make来创建?
c. 两个数组长度不同,做类型比较会相同吗?
d. slice和array区别?
e. go里面如何实现set?
f. go如何实现类似于java当中的继承机制?
g. go实现面向对象的机制?怎么去复用一个接口的方法?
h. go里面的 _
i. 并发里面channel buf设置成0和不为0有啥区别?
ⅰ. 无缓存channel的使用场景?
j. goroutine创建的时候如果要传一个参数进去有什么要注意的点?
ⅰ. https://www.cnblogs.com/waken-captain/p/10496454.html
k. 写go单元测试的规范?
l. 单步调试?
m. 导入一个go的工程,有些依赖找不到,改怎么办?
a. https://blog.csdn.net/Z_Y_D_/article/details/84646443
b. https://blog.csdn.net/flyersboy/article/details/117266318
c. https://blog.csdn.net/u010983881/article/details/75097358
d. https://kb.cnblogs.com/page/52050/
- 如何判定Slice是否是空的?(Slice判空)
绝对不能用 if slice == nil 这样的方式
因为可以创建nil的slice
- 正确方法:
len(slice) == 0
空slice和nil slice的对比,深度理解为什么 slice == nil 不可行
1 | var s1 []int // nil slice |
内存逃逸
后端 - 简单聊聊内存逃逸 | 剑指 offer - golang_个人文章 - SegmentFault 思否
go - 详解Go语言中的内存逃逸_个人文章 - SegmentFault 思否
内存逃逸危害
堆是一块没有特定结构,也没有固定大小的内存区域,可以根据需要进行调整。全局变量,内存占用较大的局部变量,函数调用结束后不能立刻回收的局部变量都会存在堆里面。变量在堆上的分配和回收都比在栈上开销大的多。对于 go 这种带 GC 的语言来说,会增加 gc 压力,同时也容易造成内存碎片。
从”栈”上逃逸到”堆”上的现象就成为内存逃逸。
逃逸分析就是指程序在编译阶段根据代码中的数据流,对代码中哪些变量需要在栈中分配,哪些变量需要在堆上分配进行静态分析的方法。堆和栈相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片,栈内存分配则会非常快。栈分配内存只需要两个CPU指令:“PUSH”和“RELEASE”,分配和释放;而堆分配内存首先需要去找到一块大小合适的内存块,之后要通过垃圾回收才能释放。所以逃逸分析更做到更好内存分配,提高程序的运行速度。
内存逃逸分析
build时添加-gcflags=-m 选项可分析内存逃逸情况,比如输出./main.go:3:6: moved to heap: x 表示局部变量x逃逸到了堆上。
避免内存逃逸的办法
- 对于小型的数据,使用传值而不是传指针,避免内存逃逸。
- 避免使用长度不固定的slice切片,在编译期无法确定切片长度,只能将切片使用堆分配。
- interface调用方法会发生内存逃逸,在热点代码片段,谨慎使用。
代码实操坑
1.字符串不能通过下标得方式去修改
报错 cannot assign to s[lenRes] (value of type byte)
1 | type stringStruct struct { |
正是因为底层是一个[]byte类型的切片,当我们使用下标的方式去修改值,这时候将一个字符内容赋值给byte类型,肯定是不允许的。但是我们可以通过下标的方式去访问对应的byte值。
所以字符串是无法被修改的,只能复制原字符串,在复制的版本上修改
方法1:转换为[]byte() (需要频繁批量修改 建议一次性都转为byte)
方法2:转换为[]rune()
方法3:新字符串代替原字符串的子字符串,用strings包中的strings.Replace()*


